Let us say we are developing a YouTube-like video streaming service, called MyTube. One particularly impressive aspect of YouTube is its global reach: regardless of where they are originally uploaded, videos are made available to audience across the globe, allowing them to quickly go viral. In general, the number of views a video garners on youtube from across the globe is a good metric for its success, and even fuels its further virality. Following YouTube, we might want MyTube to be available to viewers across the globe, and considering the importance of displaying the number of views, we might also want to equip MyTube with a view counter. MyTube’s view counter should be able to count the number of times a video was watched, notwithstanding the fact that a video can be watched simultaneously by users in different parts of the world. How do we implement such a counter?
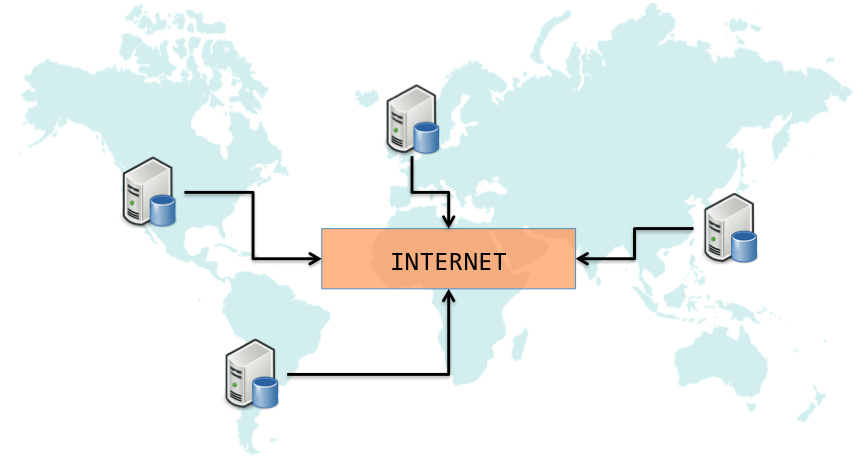
In order for MyTube to be highly available with low latency for global audience, it is imperative to geo-replicate its data across servers in different parts of the world (Each server maintains a replica of data):
Since we want to keep track of the view count for videos, we might
associate an integer count with every video_id:
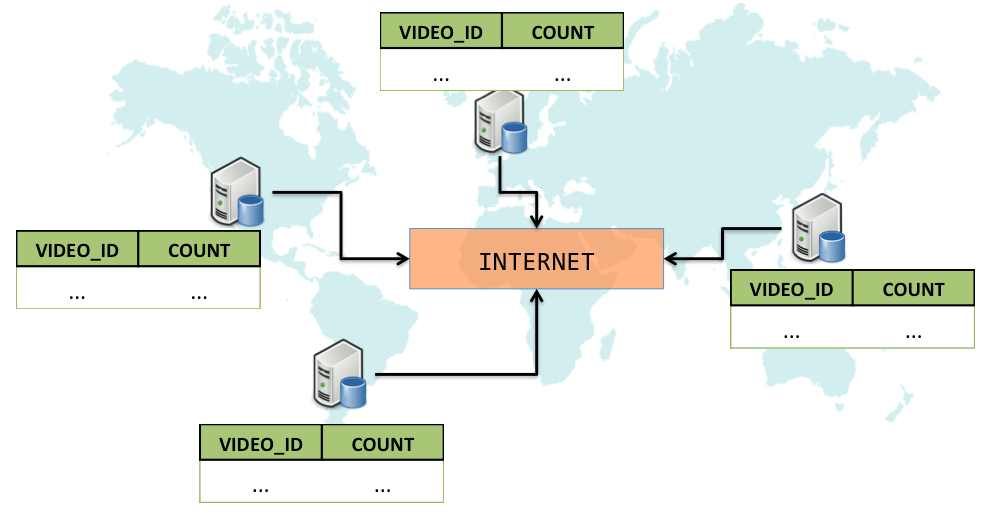
Note that count should reflect the number of views the video has
accumulated across the globe, not just at a single replica. Therefore,
whenever a video is streamed from a replica, (a). its count has to
be incremented up locally, and (b). this update needs to be propagated
to every other replica globally. One way to achieve this is by bumping
up the count synchronously across all replicas. But, synchronization
(also called strong consistency (SC)) is very expensive as
communication latency over internet is arbitrarily high, and can even
be infinite in case of network partitions:
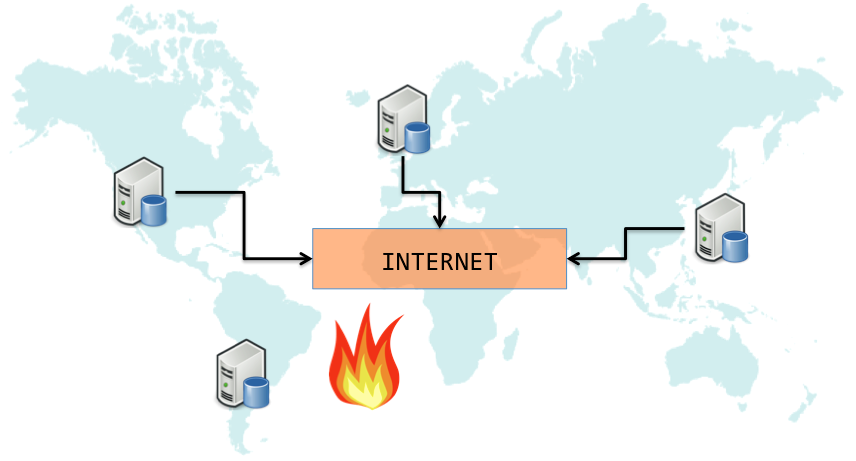
High latency means low availability, which is bad for MyTube users. This is precisely the reason why highly available services like Google and Amazon do not rely on strongly consistent data replication. In general, they rely on data stores that offer a weaker form of consistency, called Eventual Consistency(EC). Under eventual consistency, updates to multiple replicas of data are not performed synchronously. Instead, an update is first performed locally, and is only eventually propagated to all other replicas. Data stores that offer eventually consistent data replication by default are called Eventually Consistent Data Stores (ECDS). Many off-the-shelf ECDS, such as Cassandra, Riak, Redis, mongoDB, and couchDB, are available as free software over the internet. Quelea uses Cassandra as its underlying EC store. We shall now see how Quelea lets us write a highly available view counter over an eventually consistent data store, without we ever having to understand how the underlying store (Cassandra) works.