The aim of this benchmark to compare the performance of various ANSI transaction isolation levels implemented in Quelea (Namely, Read Committed (RC), Monotonic Atomic View (MAV), and Repeatable Read (RR)). For this purpose, we use a register data type with least-writer-wins semantics for writes. We compose transactions with 10 operations - 5 EC writes and 5 EC reads, execute them under different isolation levels in different experiments (one experiment per isolation level).
Building the benchmark
Since the isolation level of transactions in an experiment is fixed,
and all transactions are composed of EC reads and writes, contract
classification does nothing interesting in this benchmark. It is
therefore not necessary to build this benchmark; existing binaries can
be used. Nevertheless, if you want to build, navigate to
~/git/quelea/tests/LWW, and run make LWW_txn. Successful build
generates one binary - LWW_txn.
Running the Benchmark
First, we run a basic experiment to measure latency and throughput,
when a single client sends 1000 successive transation requests (with
an inter-request delay of 1ms (1000 μs)). We take the measurements for
each of the NoTxn, RC, MAV, and RR cases. The commands to
execute, and output generated in our sample runs are shown below. As
with the BankAccount benchmark,
experiments can be terminated either manually (via CTRL+C), or by
setting a hard time limit via --terminateAfter option, which accepts
number of seconds as argument.
NoTxn
./LWW_txn --kind Daemon --numRounds 1000 --numThreads 1 --delayReq 1000 --measureLatency --txnKind NoTxn
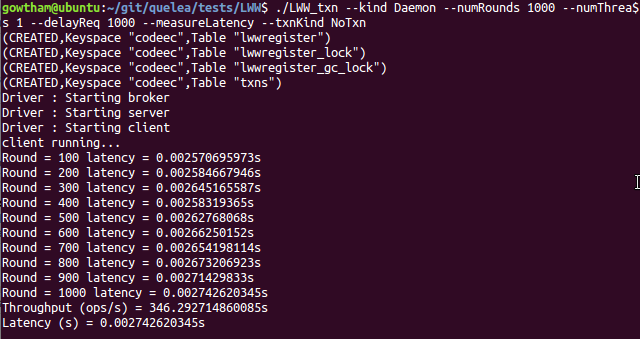
Once you have aggregate latency and throughput data, terminate the
experiment by pressing CTRL-C. If you have encountered an error, or
if you suspect that execution is not making progress, please refer to
the troubleshooting guide
for quick fix.
RC
./LWW_txn --kind Daemon --numRounds 1000 --numThreads 1 --delayReq 1000 --measureLatency --txnKind RC
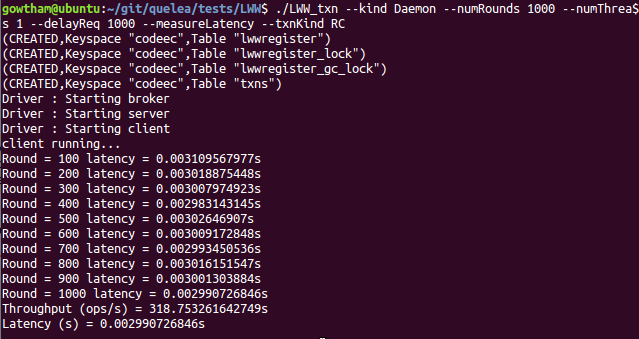
MAV
./LWW_txn --kind Daemon --numRounds 1000 --numThreads 1 --delayReq 1000 --measureLatency --txnKind MAV
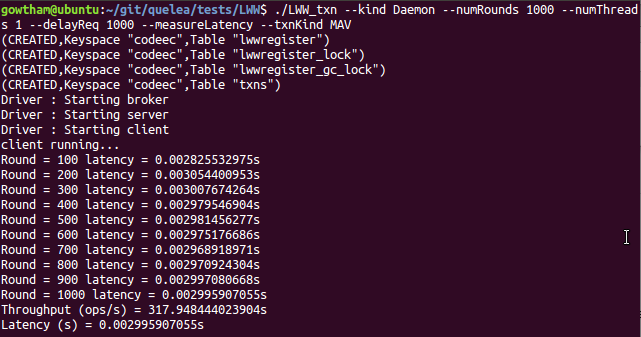
RR
./LWW_txn --kind Daemon --numRounds 1000 --numThreads 1 --delayReq 1000 --measureLatency --txnKind RR
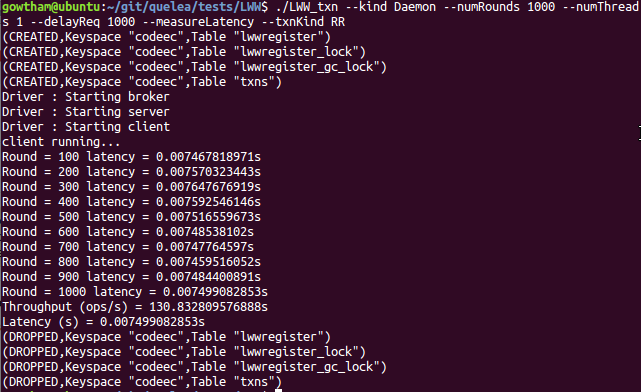
The experiment can now be repeated varying the number of client
threads (--numThreads) from 2 to 4. Screenshots capturing
measurements for sample runs when --numThreads is 4 are shown below:
NoTxn

RC

MAV

RR

Observations
As demonstrated in sample runs, experimental results should indicate that throughput depends on the strength of the isolation level of transactions:
- Througput is highest when no transactional guarantees (including atomicity) are required.
- Transactions requiring the weakest isolation level (RC) yeild highest throughput.
- Transactions requiring strongest isolation level (RR) yeild lowest throughput.