RUBiS is an eBay-like auction that allows users to browse for items, bid for items on sale, and pay for items from a wallet modelled after a bank account. To support the rich functionality, RUBiS implements a large number of operations and transactions requiring varying levels of consistency and isolation, respectively. The primary purpose of this benchmark is to study the impact of using Quelea in such a real-world setting (Fig. 9(c) of the paper); We would like to demonstrate significant performance gains obtained by annotating operations/transactions with Quelea contracts, which would otherwise need to be executed with strong consistency/isolation to guarantee correctness. Another purpose of this benchmark is to demonstrate the scalability of static contract classification, as shown in the following section.
Building the benchmark
Navigate to ~/git/quelea/tests/Rubis, and run make. On the stdout,
along with GHC’s build information, you should find something similar
to the following getting printed:
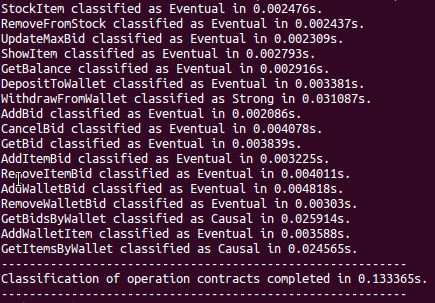
The above lines indicate the consistency class for each RUBiS operation, along with the time taken to classify the operation, and also the total time consumed by the contract classification procedure. Similar information is also displayed for RUBiS transactions:
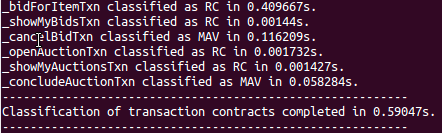
As sample runs demonstrate, compile-time overhead of classifying each operation/transaction is very low, and the total overhead of contract classification is roughly the sum of overheads incurred in each case.
Successful compilation generates two binaries - Rubis and
Rubis_strong. The former uses Quelea contracts to declare
consistency/isolation requirements of Rubis operations/transactions,
whereas the latter simply runs everything under strongest possible
consistency and isolation guarantees.
Running the Benchmark
We start with an experiment to measure latency and throughput, when
one auction is open and (the default) 3 buyers are bidding for the
item. We take the measurements for each of the Rubis and
Rubis_strong cases. The commands to execute, and output generated in
our sample runs are shown below. Like our other benchmarks,
experiments can be terminated either manually (via CTRL+C), or by
setting a hard time limit via --terminateAfter option, which accepts
number of seconds as argument.
Rubis
./Rubis --kind Daemon --numAuctions 100 --numBuyers 3 --delayReq 1000 --numItems 1
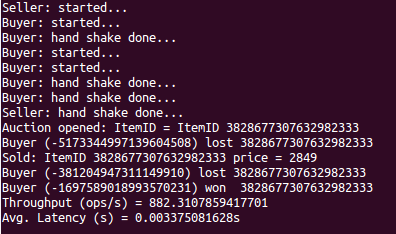
Once you have aggregate latency and throughput data, terminate the
experiment by pressing CTRL-C. If you have encountered an error, or
if you suspect that execution is not making progress, please refer to
the troubleshooting guide
for quick fix.
Rubis Strong
./Rubis_strong --kind Daemon --numAuctions 100 --numBuyers 3 --delayReq 1000 --numItems 1
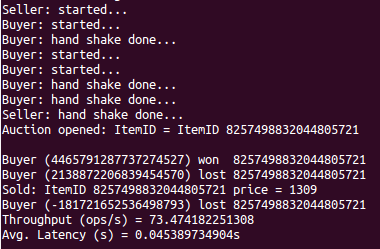
We now repeat experiments after increasing the number of concurrent auctions to 8, and number of buyers per auction to 10. Screenshots capturing measurements for sample runs are shown below:
Rubis

Rubis Strong

Observations
As demonstrated in sample runs, experiments should let us infer that,
while both Rubis and Rubis_strong preserve necessary semantic
guarantees (e.g: only the buyer who wins the auction gets billed), the
former does so while delivering orders of magnitude higher throughput
and lower latency than the latter.