Ezirmin : An easy interface to the Irmin library
15 Feb 2017Ezirmin is an easy interface over the Irmin, a library database for building persistent mergeable data structures based on the principles of Git. In this post, I will primarily discuss the Ezirmin library, but also discuss some of the finer technical details of mergeable data types implemented over Irmin.
Contents
Irmin and Ezirmin
Irmin is a library for manipulating persistent mergeable data structures (including CRDTs) that follows the same principles of Git. In particular, it has built-in support for snapshots, branches and reverts, and can compile to multiple backends. Being written in pure OCaml, apps written using Irmin, as well as running natively, can run in the browsers or be compiled to Unikernels. A good introduction to the capabilities of Irmin can be found in the Irmin README file.
One of the downsides to being extremely configurable is that the Irmin library is not beginner friendly. In particular, the library tends to be rather functor heavy, and even simple uses require multiple functor instantiations1. The primary goal of Ezirmin is to provide a defuntorized interface to Irmin, specialized to useful defaults. However, as I’ve continued to build Ezirmin, it has come to include a collection of useful mergeable data types including counters, queues, ropes, logs, etc. I will spend some time describing some of the interesting aspects of these data structures.
Quick tour of Ezirmin
You can install the latest version of Ezirmin by
$ git clone https://github.com/kayceesrk/ezirmin
$ cd ezirmin
$ opam pin add ezirmin .
Stable versions are also available through OPAM:
$ opam install ezirmin
Let’s fire up utop and get started:
$ utop
utop # #require "ezirmin";;
utop # open Lwt.Infix;;
We’ll create a mergeable queue of strings using the Git file system backend
rooted at /tmp/ezirminq:
utop # module M = Ezirmin.FS_queue(Tc.String);; (* Mergeable queue of strings *)
utop # open M;;
utop # let m = Lwt_main.run (init ~root:"/tmp/ezirminq" ~bare:true () >>= master);;
val m : branch = <abstr>
m is the master branch of the repository. Ezirmin exposes a key value store,
where keys are hierarchical paths and values are whatever data types is stored in
the repo. In this case, the data type is a queue. Let’s push some elements into
the queue:
utop # push m ["home"; "todo"] "buy milk";;
- : unit = ()
utop # push m ["work"; "todo"] "publish ezirmin";;
- : unit = ()
utop # to_list m ["home"; "todo"];;
- : string list = ["buy milk"]
The updates to the queue is saved in the Git repository at /tmp/ezirminq. In
another terminal,
$ utop
utop # #require "ezirmin";;
utop # module M = Ezirmin.FS_queue(Tc.String);; (* Mergeable queue of strings *)
utop # open M;;
utop # open Lwt.Infix;;
utop # let m = Lwt_main.run (init ~root:"/tmp/ezirminq" ~bare:true () >>= master);;
val m : branch = <abstr>
utop # pop m ["home"; "todo"];;
- : string option = Some "buy milk"
For concurrency control, use branches. In the first terminal,
utop # let wip = Lwt_main.run @@ clone_force m "wip";;
utop # push wip ["home"; "todo"] "walk dog";;
- : unit = ()
utop # push wip ["home"; "todo"] "take out trash";;
- : unit = ()
The changes are not visible until the branches are merged.
utop # to_list m ["home"; "todo"];;
- : string list = []
utop # merge wip ~into:m;;
- : unit = ()
utop # to_list m ["home"; "todo"];;
- : string list = ["walk dog"; "take out trash"]
Merge semantics
What should be the semantics of popping the queue at home/todo concurrently
at the master branch and wip branch? It is reasonable to ascribe exactly once
semantics to pop such that popping the same element on both branches and
subsequently merging the queues would lead to a merge conflict. However, a more
useful semantics is where we relax this invariant and allow elements to be
popped more than once on different branches. In particular, the merge operation
on the queue ensures that:
- An element popped in one of the branches is not present after the merge.
- Merges respect the program order in each of the branches.
- Merges converge.
Hence, our merge queues are CRDTs.
Working with history
Irmin is fully compatible with Git. Hence, we can explore the history of the operations using the git command line. In another terminal:
$ cd /tmp/ezirminq
$ git lg
* e75da48 - (4 minutes ago) push - Irmin xxxx.cam.ac.uk.[73126] (HEAD -> master, wip)
* 40ed32d - (4 minutes ago) push - Irmin xxxx.cam.ac.uk.[73126]
* 6a56fb0 - (5 minutes ago) pop - Irmin xxxx.cam.ac.uk.[73221]
* 6a2cc9a - (6 minutes ago) push - Irmin xxxx.cam.ac.uk.[73126]
* 55f7fc8 - (6 minutes ago) push - Irmin xxxx.cam.ac.uk.[73126]
The Git log shows that there have been 4 pushes and 1 pop in this repository. In addition to the data structures being mergeable, they are also persistent. In particular, every object stored in Irmin has complete provenance. You can also manipulate history using the Git command line.
$ git reset HEAD~2 --hard
$ git lg
* e75da48 - (8 minutes ago) push - Irmin xxxx.cam.ac.uk.[73126] (wip)
* 40ed32d - (9 minutes ago) push - Irmin xxxx.cam.ac.uk.[73126]
* 6a56fb0 - (9 minutes ago) pop - Irmin xxxx.cam.ac.uk.[73221] (HEAD -> master)
* 6a2cc9a - (10 minutes ago) push - Irmin xxxx.cam.ac.uk.[73126]
* 55f7fc8 - (10 minutes ago) push - Irmin xxxx.cam.ac.uk.[73126]
Back in the first terminal:
utop # to_list m ["home"; "todo"];;
- : string list = []
Since we rolled back the master to before the pushes were merged, we see an empty list. Ezirmin also provides APIs for working with history programmatically.
utop # let run = Lwt_main.run;;
utop # let repo = run @@ init ();;
utop # let path = ["Books"; "Ovine Supply Logistics"];;
utop # let push_msg = push m ~path;;
utop # begin
push_msg "Baa" >>= fun () ->
push_msg "Baa" >>= fun () ->
push_msg "Black" >>= fun () ->
push_msg "Camel"
end;;
utop # to_list m path;;
- : string list = ["Baa"; "Baa"; "Black"; "Camel"]
Clearly this is wrong. Let’s fix this by reverting to earlier version:
utop # let m_1::_ = run @@ predecessors repo m;; (** HEAD~1 version *)
utop # to_list m_1 path;;
- : string list = ["Baa"; "Baa"; "Black"]
utop # update_branch m ~set:m_1;;
utop # to_list m path;;
- : string list = ["Baa"; "Baa"; "Black"]
Now that we’ve undone the error, we can do the right thing.
utop # push_msg "Sheep";;
utop # run @@ to_list m path;;
- : string list = ["Baa"; "Baa"; "Black"; "Sheep"]
Reacting to changes
Ezirmin supports watching a particular key for updates and invoking a callback function when there is one.
utop # let cb _ = Lwt.return (print_endline "callback: update to home/todo");;
utop # watch m ["home"; "todo"] cb
The code above installs a listener cb on the queue at home/todo, which is
run every time the queue is updated. This includes local push and pop
operations as well as updates due to merges.
utop # push m ["home"; "todo"] "hang pictures";;
callback: update to home/todo
- : unit = ()
Interaction with remotes
Unlike distributed data stores, where the updates are disseminated
transparently between the replicas, Ezirmin provides you the necessary building
blocks for building your own dissemination protocol. As with Git, Ezirmin
exposes the functionality to push2 and pull changes from remotes.
#show_module Sync;;
module Sync : sig
type remote
val remote_uri : string -> remote
val pull : remote -> branch -> [ `Merge | `Update ] -> [ `Conflict of string | `Error | `No_head | `Ok ] Lwt.t
val push : remote -> branch -> [ `Error | `Ok ] Lwt.t
end
This design provides the flexibility to describe your own network layout, with anti-entropy mechanisms built-in to the synchronization protocol. For example, one might deploy the replicas in a hub-and-spoke model where each replica accepts client writes locally and periodically publishes changes to the master and also fetches any latest updates. The data structures provided by Ezirmin are always mergeable and converge. Hence, the updates are never rejected. It is important to note that even though we have a centralized master, this deployment is still highly available. Even if the master is unavailable, the other nodes can still accept client requests. The replicas may also be connected in a peer-to-peer fashion without a centralized master for a more resilient deployment.
Mergeable persistent data types
Ezirmin is equipped with a growing collection of mergeable data types. The mergeable datatypes occupy a unique position in the space of CRDTs. Given that we have the history, the design of mergeable datatypes is much simpler. Additionally, this also leads to richer structures typically not found in CRDTs. It is worth studying them in detail.
Irmin Architecture
Irmin provides a high-level key-value interface built over two lower level heaps: a block store and a tag store. A block store is an append-only content-addressable store that stores serialized values of application contents, prefix-tree nodes, history meta-data, etc. Instead of using physical memory address of blocks, the blocks are identified by the hash of their contents. As a result block store enjoys very nice properties. Being content-addressed, we get sharing for free: two blocks with the same content will have the have the same hash. This not only applies for individual blocks, but also for linked-structures. For example,
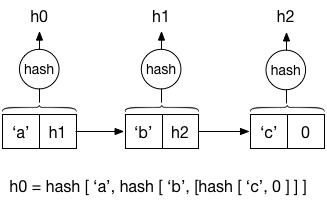
The linked list above is uniquely identified by hash h0 since h0 was
computed from the content a and the hash of the tail of the list h1. No
other list has hash h0. Changing c to C in this list would result in a
different hash for the head of the list3. Moreover, since the block
store is append-only, all previous versions of a application-level data
structure is also available, and thus providing persistence. This also makes for
a nice concurrency story for multiple processes/threads operating on the block
store. The absence of mutations on block store mean that no additional
concurrency control mechanisms are necessary.
The only mutable part of the Irmin architecture is the tag store, that maps global names to blocks in the block store. The notion of branches are built on top of the tag store. Cloning a branch creates a new tag that points to the same block as the cloned branch.
User-defined merges
The real power of Irmin is due to the user-defined merges. Irmin expects the developer to provide a 3-way merge function with the following signature:
type t
(** User-defined contents. *)
val merge : old:t -> t -> t -> [`Ok of t | `Conflict of string]
(** 3-way merge. *)
Given the common ancestor old and the two versions, merge function can either
return a successful merge or mark a conflict. It is up to the developer to ensure
that merges are commutative (merge old a b = merge old b a) and that the merge
captures the intent of the two branches. If the merge function never conflicts,
we have CRDTs.
Mergeable Counters
The simplest mergeable data type is a counter with an increment and decrement operations. Given that we have a 3-way merge function, the merge is intuitive:
Given the two new values for the counter t1 and t2, and their lowest common
ancestor value old, the new value of the counter is the sum of the old value
and the two deltas: old + (t1 - old) + (t2 - old) = t1 + t2 - old.
Theory of merges
While this definition is intuitive, the proof of why this strategy (i.e., computing deltas and applying to the common ancestor) is correct is quite subtle. It happens to be the case that the patches (deltas) in this case, integers under addition, form an abelian group. Judah Jacobson formalizes patches for Darcs as inverse semigroups and proves convergence. Every abelian group is also an inverse semigroup. Hence, the above strategy is correct. Merges can also be equivalently viewed as a pushout in category theory, leading to the same result. I will have to save the discussion of the category theoretic reasoning of Irmin merges for another time. But Liam O’Connor has written a concise post on the theory of patches which is worth a read.
Recursive merges
Since Ezirmin allows arbitrary branching and merging, the lowest common ancestor need not be unique. One way to end up with multiple lowest common ancestors is criss-cross merges. For example, consider the history graph below:
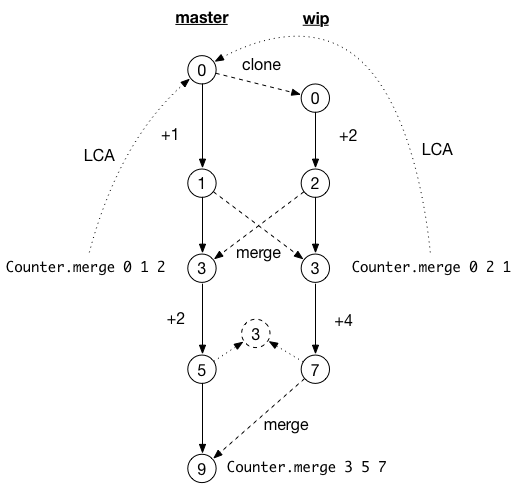
The counter at some key in the master was initially 0. The branch wip was
cloned at this point. The counter is incremented by 1 at master and 2 at
wip. At this point, both branches are merged into the other branch. The common
ancestor here is the initial state of counter 0. This results in counter value
of 3 in both branches. Suppose there are further increments, 2 at master
and 4 at wip, resulting in counter values 5 and 7 respectively in
master and wip.
If the wip branch is now merged in master, there are two lowest common
ancestors: the commit with value 1 at master and 2 in wip. Since the 3-way
merge algorithm only work for a single common ancestor, the we adopt a recursive
merge strategy, where the lowest common ancestors are first merged resulting in
a internal commit with value 3 (represented by a dotted circle). This commit
is now used as the common ancestor for merging, which results in 9 as the new
state of the counter. This matches the increments done in both branches. The
recursive merge strategy is also the default merge strategy for Git.
Mergeable logs
Another useful data type is mergeable logs, where each log message is a string. The merge operation accumulates the logs in reverse chronological order. To this end, each log entry is a pair of timestamp and message, and the log itself is a list of entries. They are constructed using mirage-tc:
The merge function extracts the newer entries from either branches, sorts them and appends to the front of the old list.
While this implementation is simple, it does not scale well. In particular, each
commit stores the entire log as a single serialized blob. This does not take
advantage of the fact that every commit can share the tail of the log with its
predecessor. Moreover, every append to the log needs to deserialize the entire
log, append the new entry and serialize the log again. Hence, append is an
O(n) operation, where n is the size of the log. Merges are also worst case
O(n). This is undesirable.
Efficient mergeable logs
We can implement a efficient logs by taking advantage of the fact that every commit shares the tail of the log with its predecessor.
type log_entry = {
time : Time.t;
message : V.t; (** V.t is type of message. *)
prev : K.t option (** K.t is the type of address in the block store. *)
}
Merges simply add a new node which points to the logs of merged branches, resulting in a DAG that captures the causal history. The following sequence of operations:
utop # #require "ezirmin";;
utop # open Lwt.Infix;;
utop # module M = Ezirmin.Memory_log(Tc.String);;
utop # open M;;
utop # let m = Lwt_main.run (init () >>= master);;
utop # Lwt_main.run (
append m [] "m0" >>= fun _ ->
append m [] "m1" >>= fun _ ->
clone_force m "wip" >>= fun w ->
append w [] "w0" >>= fun _ ->
append m [] "m2" >>= fun _ ->
merge w ~into:m >>= fun _ ->
append w [] "w1" >>= fun _ ->
append w [] "w2" >>= fun _ ->
append m [] "m3" >>= fun _ ->
append m [] "m4"
);;
results in the heap below.
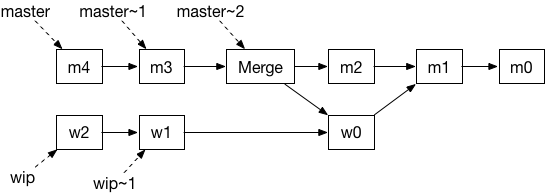
Read traverses the log in reverse chronological order.
utop # read_all m [];;
- : string list = ["m4"; "m3"; "m2"; "w0"; "m1"; "m0"]
This implementation has O(1) appends and O(1) merges, resulting in much
better performance. The graph below compares the blob log implementation and
this linked implementation with file system backend by performing repeated
appends to the log and measuring the latency for append.
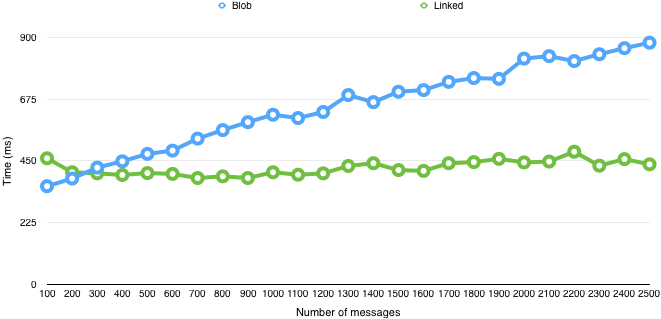
Each point represents the average latency for the previous 100 appends. The results show that the append latency for linked implementation remains relatively constant while the blob implementation slows down considerably with increasing number of appends. Additionally, the linked implementation also supports efficient paginated reads.
Mergeable ropes
A rope data structure is used for efficiently storing and manipulating very long strings. Ezirmin provides mergeable ropes where for arbitrary contents, but also specialized for strings. Ropes automatically rebalance to maintain the invariant that the height of the tree is proportional to the length of the contents. The crux of the merge strategy is that given a common ancestor and the two trees to be merged, the merge algorithm works out the smallest subtrees where the modification occurred. If the modifications are on distinct subtrees, then the merge is trivial.
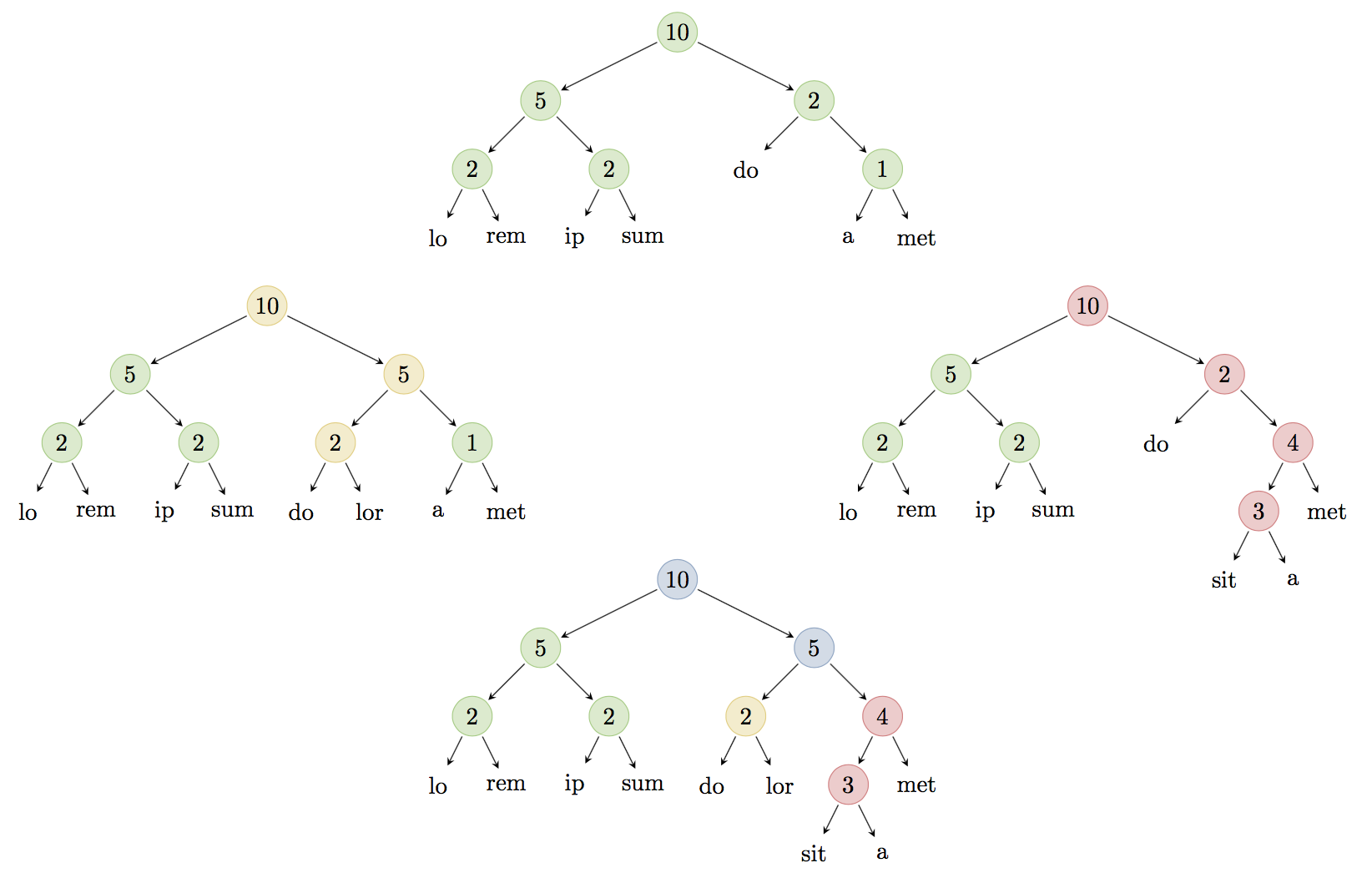
If the modification is on the same subtree, then the algorithm delegates to merge the contents. This problem has been well studied under the name of operational transformation (OT). OT can be categorically explained in terms of pushouts. Mergeable strings with insert, delete and replace operations are isomorphic to counters with increment and decrement. We apply a similar strategy to merge string.
First we compute the diff between the common ancestor and the new tree using Wagner-Fischer algorithm. Then we transform one patch with respect to the other using standard OT definition such that we can first apply one of the original patch to the common ancestor and then apply the transformed patch of the other branch to get the result tree.
For example,
utop # #require "ezirmin";;
utop # open Lwt.Infix;;
utop # open Ezirmin.Memory_rope_string;;
utop # let m = Lwt_main.run (init () >>= master);;
utop # let t = Lwt_main.run (
make "abc" >>= fun t ->
write m [] t >>= fun _ ->
Lwt.return t
);;
utop # let w = Lwt_main.run (clone_force m "w");;
utop # let _ = Lwt_main.run (
set t 1 'x' >>= fun t' (* "axc" *) ->
write m [] t' >>= fun _ ->
insert t 1 "y" >>= fun t' (* "aybc" *)->
write w [] t' >>= fun _ ->
merge w ~into:m >>= fun _ (* "ayxc" *) ->
merge m ~into:w
);;
utop # Lwt_main.run (
read m [] >>= function
| None -> failwith "impossible"
| Some r -> flush r >|= fun s ->
Printf.printf "m is \"%s\"\n" s
);;
- : unit = ()
m is "ayxc"
utop # Lwt_main.run (
read w [] >>= function
| None -> failwith "impossible"
| Some r -> flush r >|= fun s ->
Printf.printf "w is \"%s\"\n" s
)
- : unit = ()
w is "ayxc"
The combination of mergeable ropes with OT gets the best of both worlds. Compared to a purely OT based implementation, diffs are only computed if updates conflict at the leaves. The representation using ropes is also efficient in terms of storage where multiple versions of the tree shares blocks. A purely rope based implementation either has the option of storing individual characters (atoms) at the leaves (and resolve conflicts based on some deterministic mechanism such as timestamps or other deterministic strategies) or manifest the conflict at the leaves to the user to get it resolved. A simple strategy might be to present both of the conflicting strings, and ask the user to resolve it. Hence, mergeable ropes + OT is strictly better than either of the approaches.
Next steps
Ezirmin is open to comments and contributions. Next steps would be:
- Implement more mergeable data types
- Implement generic mergeable datatypes using depyt.
- Explore the data types which admit conflicts. For example, a bank account with
non-negative balance does not form a CRDT with a
withdrawoperation. However, operations such asdepositandaccrue_interestcan be coordination-free.
Footnotes
-
Things are indeed improving with a cleaner API in the 1.0 release. ↩
-
Push is currently broken. But given that Irmin is compatible with git, one can use
git-pushto publish changes. ↩ -
The same principle underlies the irrefutability of blockchain. No block can be changed without reflecting the change in every subsequent block. ↩
