A deep dive into Multicore OCaml garbage collector
06 Jul 2017
I recently gave a talk on the internals of multicore OCaml GC at Jane Street
offices in NYC. The slides from the talk are available
online. But I felt that
the slides alone aren’t particularly edifying. This post is basically the slides
from the talk annotated with notes.
Abstract
In a mostly functional language like OCaml, it is desirable to have each domain
(our unit of parallelism) collect its own local garbage independently. Given
that OCaml is commonly used for writing latency sensitive code such as trading
systems, UIs, networked unikernels, it is also desirable to minimise the
stop-the-world phases in the GC. Although obvious, the difficulty is to make
this work in the presence of mutations and concurrency. In this talk, I will
present the overall design of Multicore OCaml GC, but also deep dive into a few
of the interesting techniques that make it work.
Slidedeck
Slide of
( ← and → arrow keys also work)
Multicore OCaml project is led from OCaml Labs within the University of
Cambridge. Stephen Dolan begun the project
while procrastinating on writing up his dissertation. Hurray to that!
Multicore OCaml extends OCaml with native support for concurrency and
parallelism. Unlike many other languages, we clearly separate concurrency from
parallelism in the language. Concurrency in Multicore OCaml is expressed through
lightweight language level threads called fibers. The unit of
parallelism is a domain, which maps to kernel threads. Many kernel
threads may service a particular domain, but only one of those kernel threads
ever runs OCaml code. A typical program is expected to have a large number of
fibers mapped over a few domains. In this talk, I provide an overview of the
Multicore OCaml GC design, with a few deep dives into some of the interesting
and novel techniques.
It is difficult to appreciate the subtleties of the choice of GC techniques in
isolation. So we shall begin with a sane setup - a GC for a sequential purely
functional language. We shall subsequently extend the language with series of
reprehensible extensions including mutations, parallelism and concurrency, in
that order, and observe how the sane setup falls apart and what we shall do to
recover sanity while retaining efficiency. The early parts of the talk should be
unsurprising to someone familiar with GC internals, but is useful for setting up
the latter material.
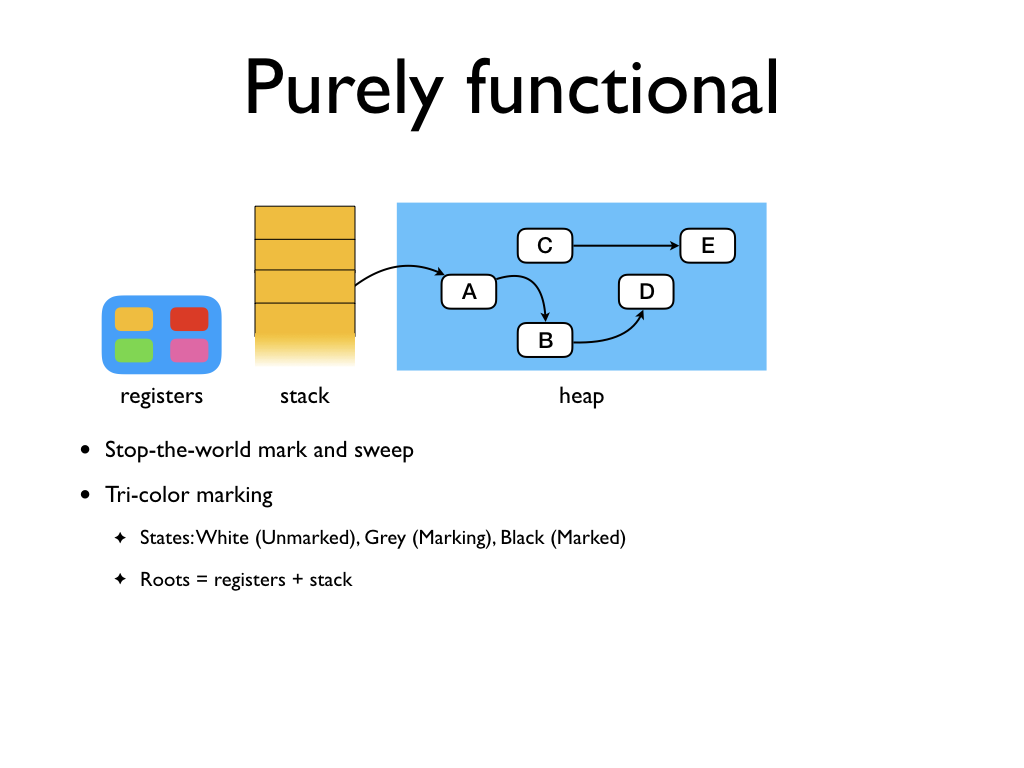
The figure shows the snapshot of the runtime state of a sequential purely
functional language. We have a set of objects allocated on the heap. These
objects may be pointed to be other heap objects as well as any of the registers
and the current runtime stack. The simplest GC strategy is to stop the program
and perform a mark-and-sweep garbage collection. The core idea is that we start
from the roots of the program state i.e., current stack and registers, and
perform a depth-first traversal through the object graph. Any unreachable
objects are garbage and they can be reclaimed.
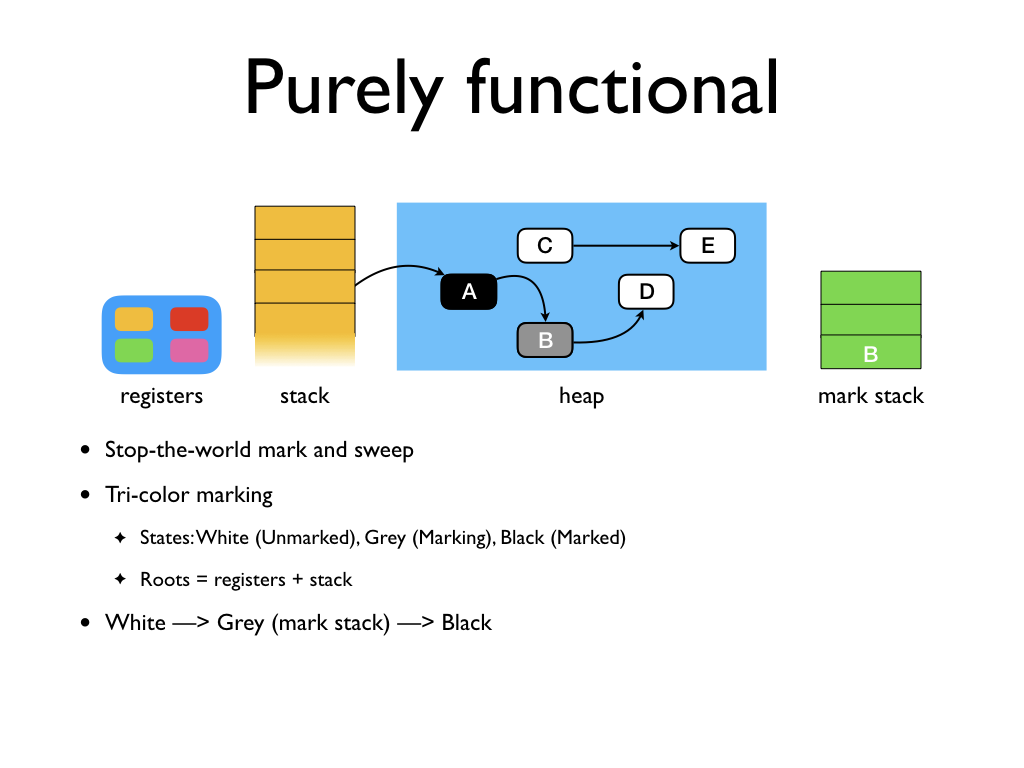
Tri-colour marking is a standard marking algorithm. During marking, the objects
are in one of three states: white(unmarked), grey(marking) and black(marked).
At the beginning of the GC, all objects are white. The GC marks grey any white
object it finds and pushes it into the mark stack. Subsequently, objects are
popped off the mark stack, all of its white children marked, and the object is
marked black. We have the invariant that a black object does not point to a
white object. This is called the tri-colour invariant. The figure shows the
state when object A and its children have been marked (hence, A is black),
object B has been marked grey and is on the mark stack.
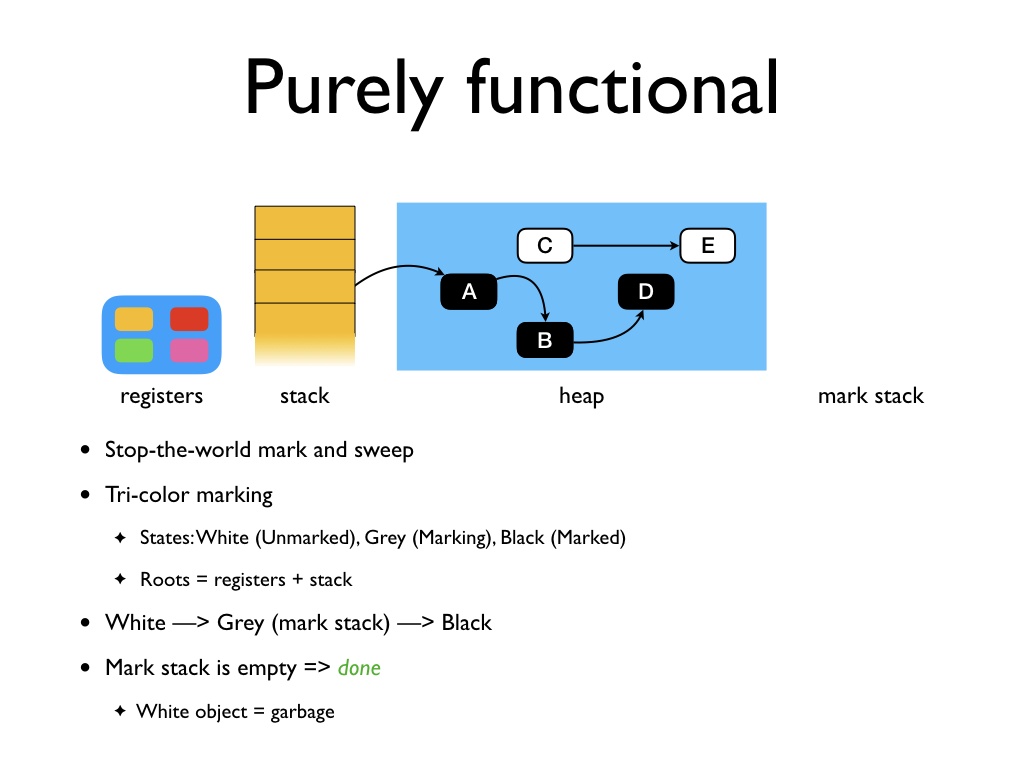
GC is done when the mark stack is empty. At this point, all reachable objects
are black. Any unreachable objects are white. A sweeper examines all the
allocated objects, and marks any object still white as free space that can
subsequently be reused.
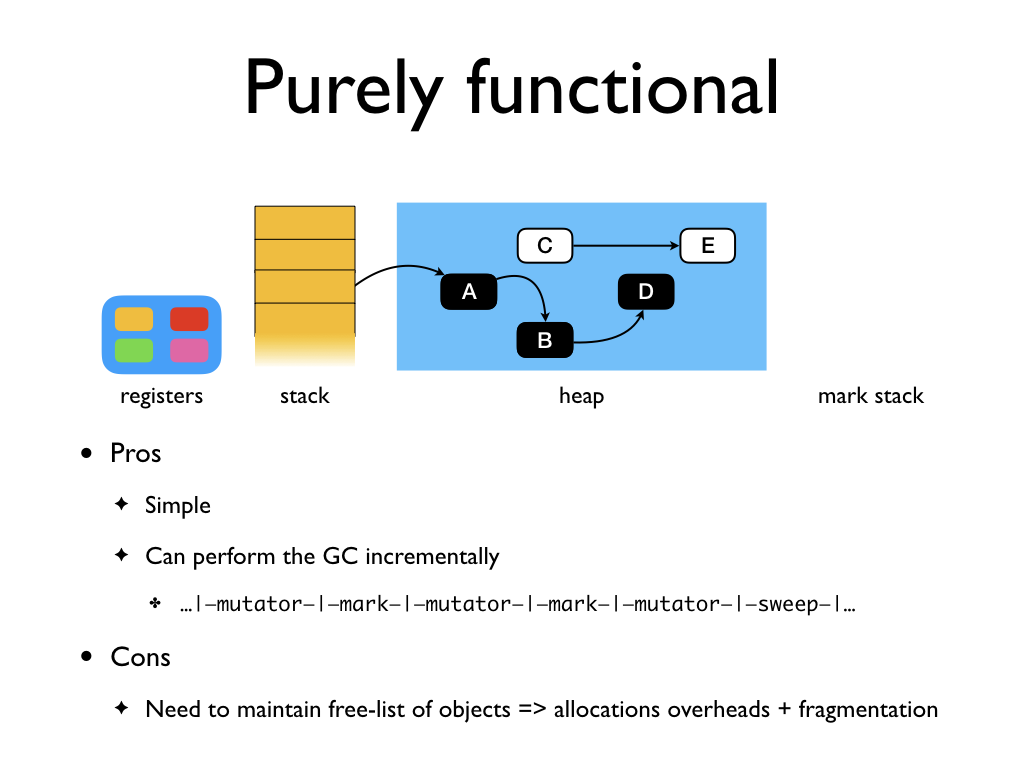
Mark and sweep GC has several advantages. For starters, it is a very simple
algorithm as GC algorithms go. The algorithm is also naturally incremental. The
mutator (OCaml code) and the GC work can alternate between each other,
minimizing the pause times in the GC. However, the primary disadvantage with
this scheme is that one needs to maintain a free-list of objects for
allocations. While there are many algorithms to find the best place to allocate
an object, all of them have non-trivial overheads. Functional programming
languages have high rate of allocation and would benefit fast allocations.
Moreover, free-list implementations also suffer from fragmentation.
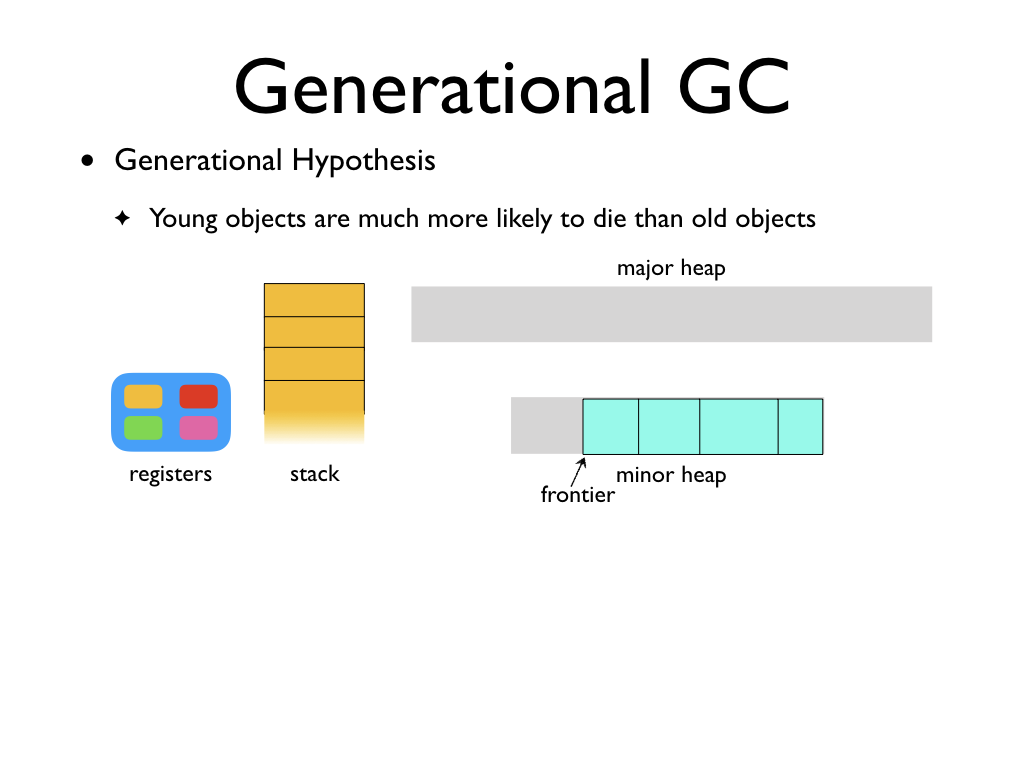
To alleviate this, functional programming languages typically implement a
generational GC. Generational hypothesis says that the young objects are far
more likely to die than older objects. To take advantage of this, the heap is
split into two -- a small minor heap, where new objects are allocated and a
larger major heap. In particular, objects in the minor heap are allocated by
bumping the frontier, leading to fast allocations. When the minor heap is full,
we garbage collect the minor heap.
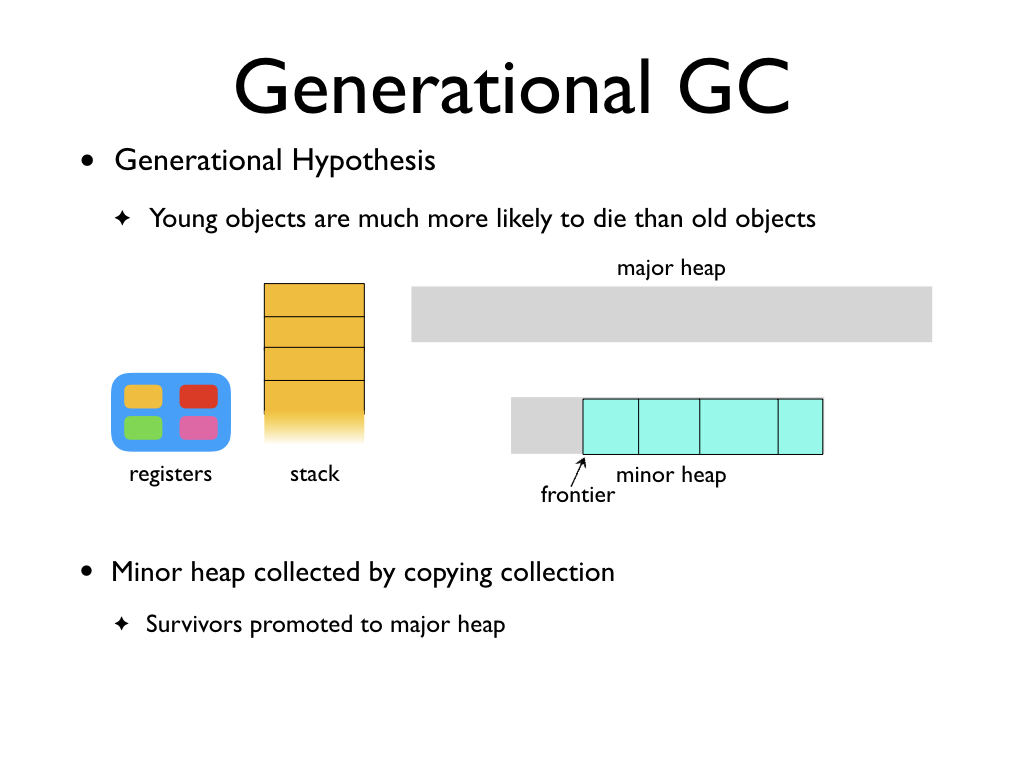
Minor heap is GCed with a copying collector, and any object that survives the
minor GC is promoted to the major GC. A nice aspect of copying collection for
minor GC is that only the live objects need to be scanned, unlike mark and sweep
collection where the sweeper needs to examine every allocated object. Given the
generational hypothesis, we will not examine most of the objects in the minor
heap. As a data point, the minor GC survival rate while compiling the OCaml
compiler is around 10%.
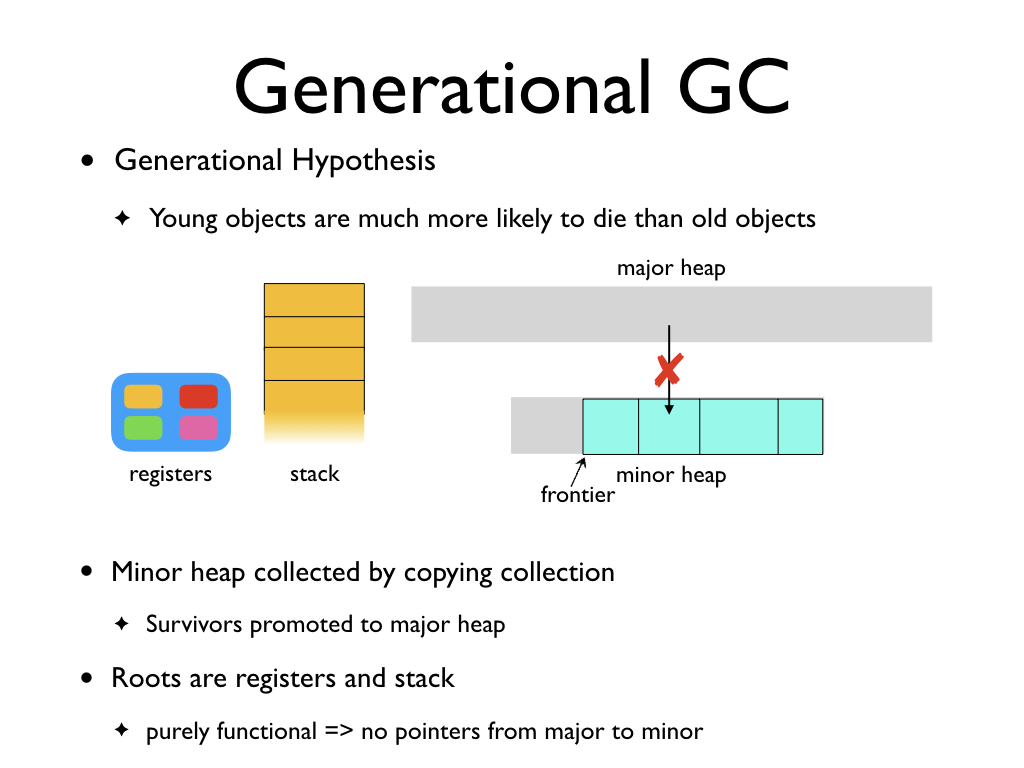
The roots for the minor collection are the current stack and the live register
set. Since our language is purely functional, there will be no pointers from the
major heap to the minor heap. This is because all the objects in major heap are
older than all the objects in the minor heap. The lack of mutations mean that an
object can only point to an older object. Hence, we don't need to care about
objects in the major heap for minor collections.
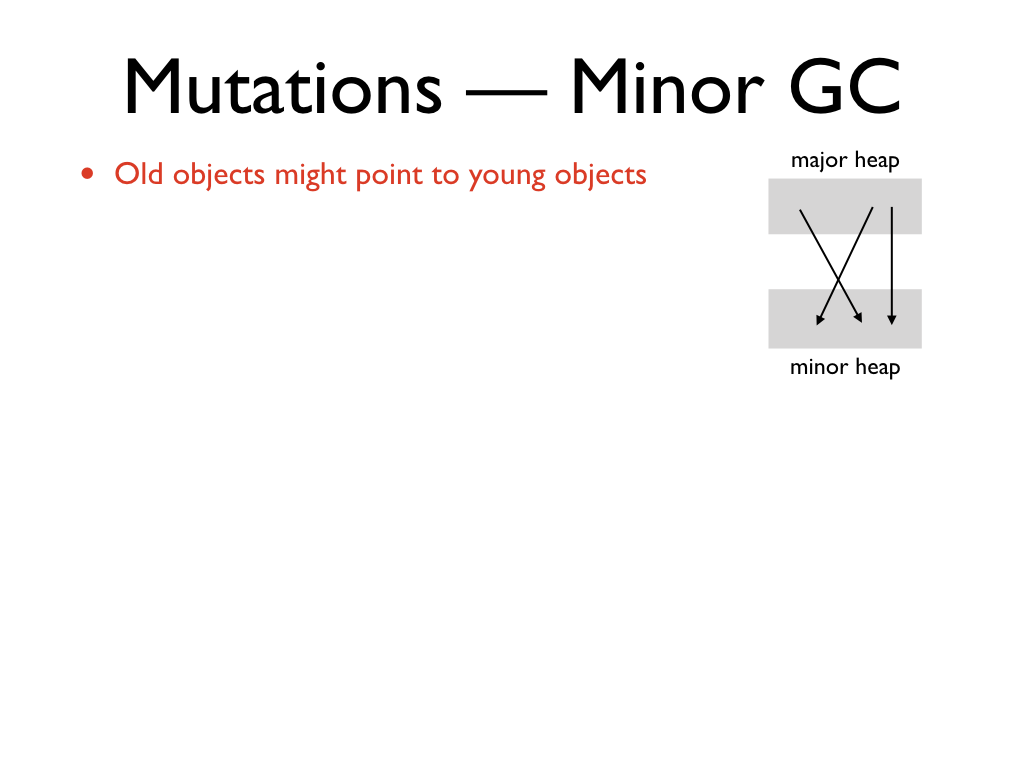
With mutations, the major heap may point to the minor heap. For example, by
assigning a minor heap object to a major heap reference. We need to know these
references so that we can treat them as roots for the minor collection.
Naively, we can scan the entire major heap for every minor GC to find such
pointers. But this is impractical.
Instead, we intercept the writes with a write barrier that records such
pointers in an auxiliary data structure called the remembered set.
Remembered set holds the set of pointers from the major heap to the minor heap,
and is used as the root for minor collections. After the minor collection, the
remembered set is cleared.
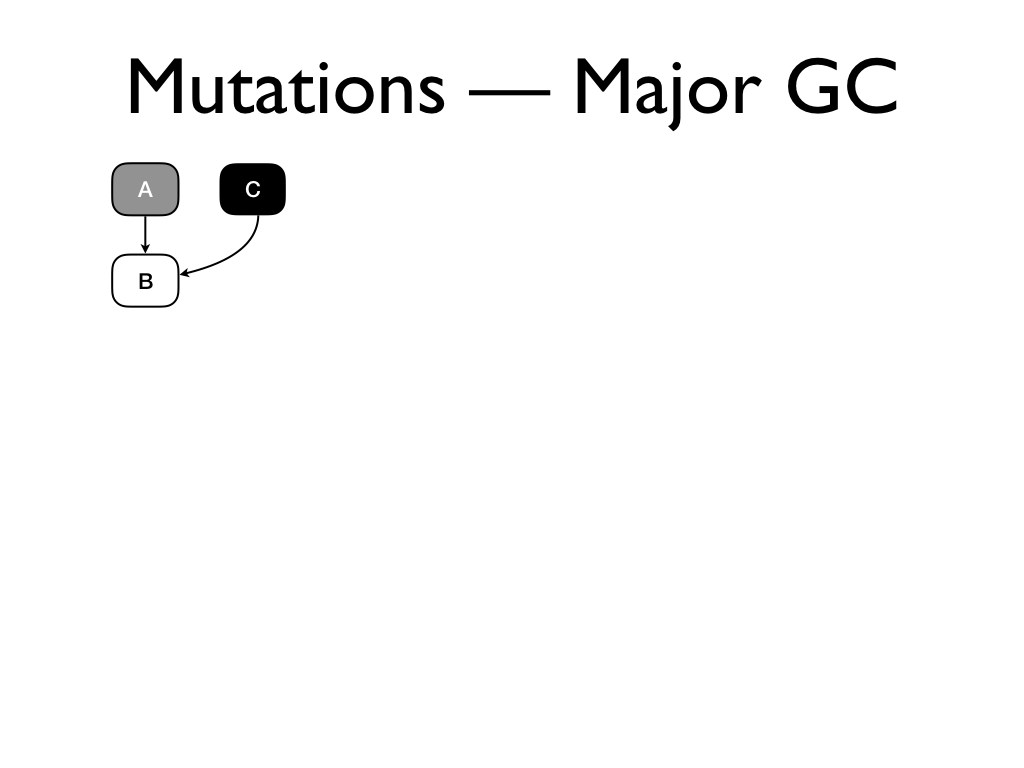
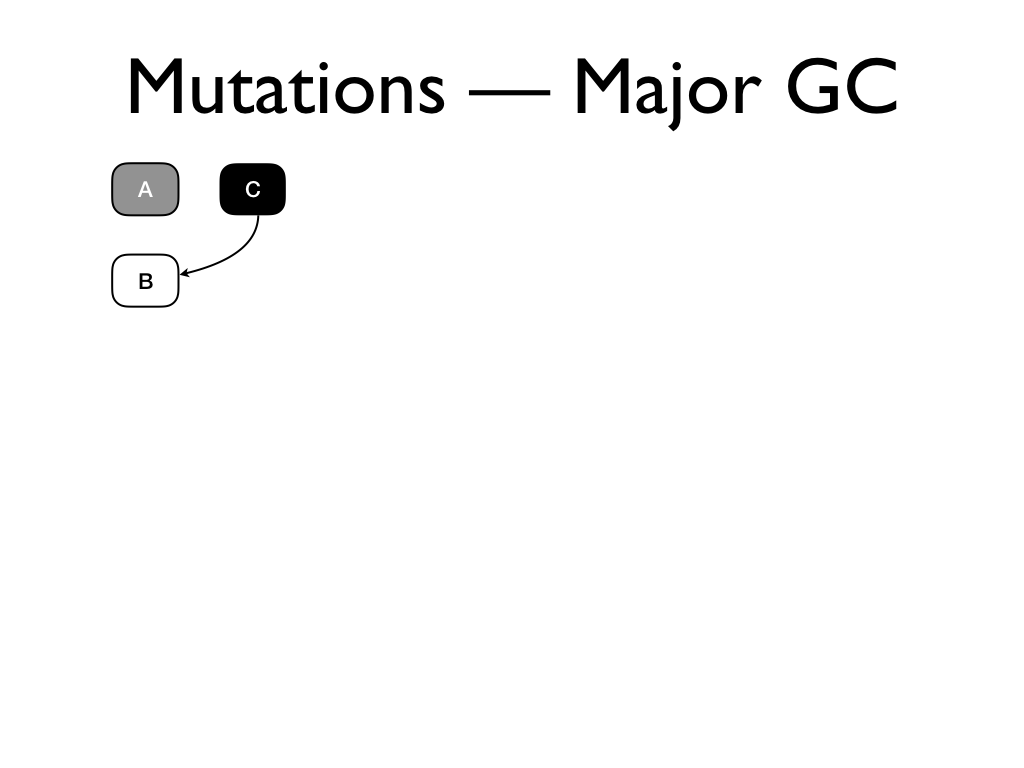
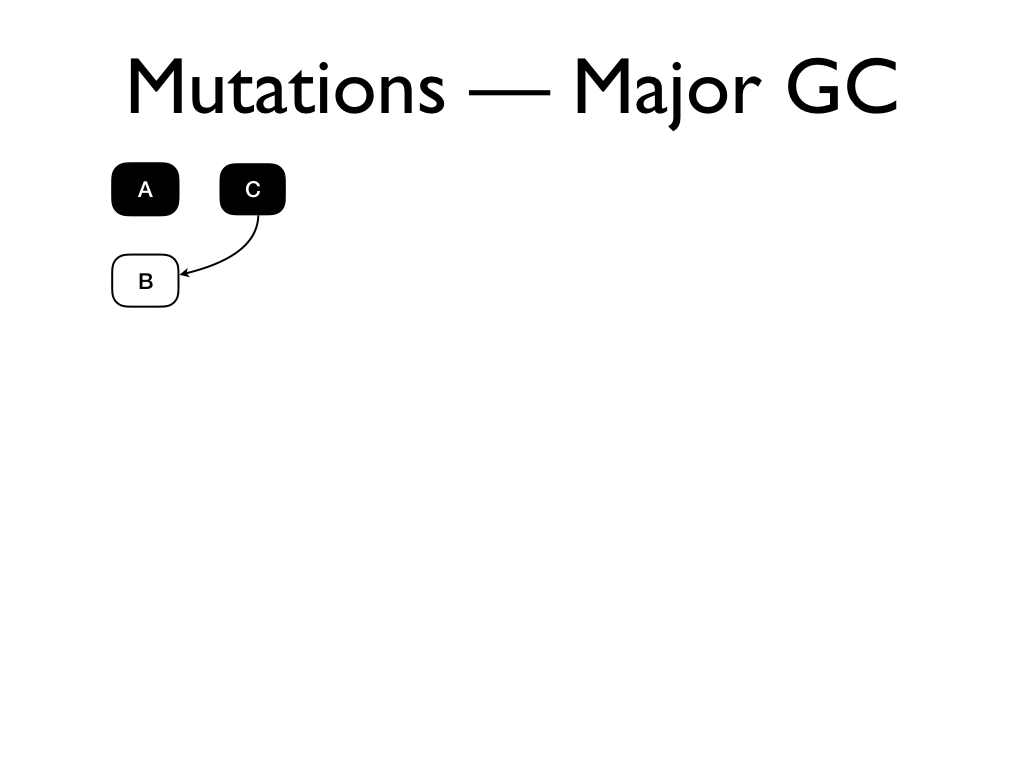
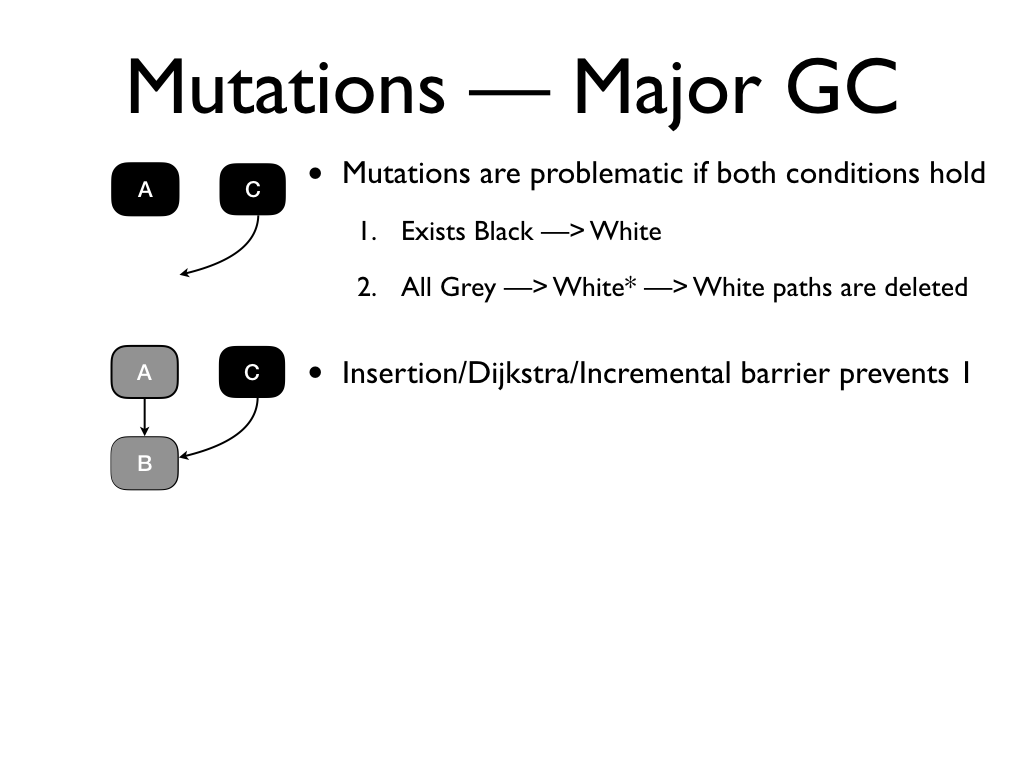
Mutations breaks tri-colour invariant. Suppose our heap has these three
objects...
and we assign the white object B to the
black object C...
and we subsequently delete the pointer from A to B.
If we perform a major GC now,
A will be eventually marked as black. But
the white object B is only pointed to by
the black object C, which will not be
marked,
and the sweeper will mark it as free. This leaves the heap in an inconsistent
state.
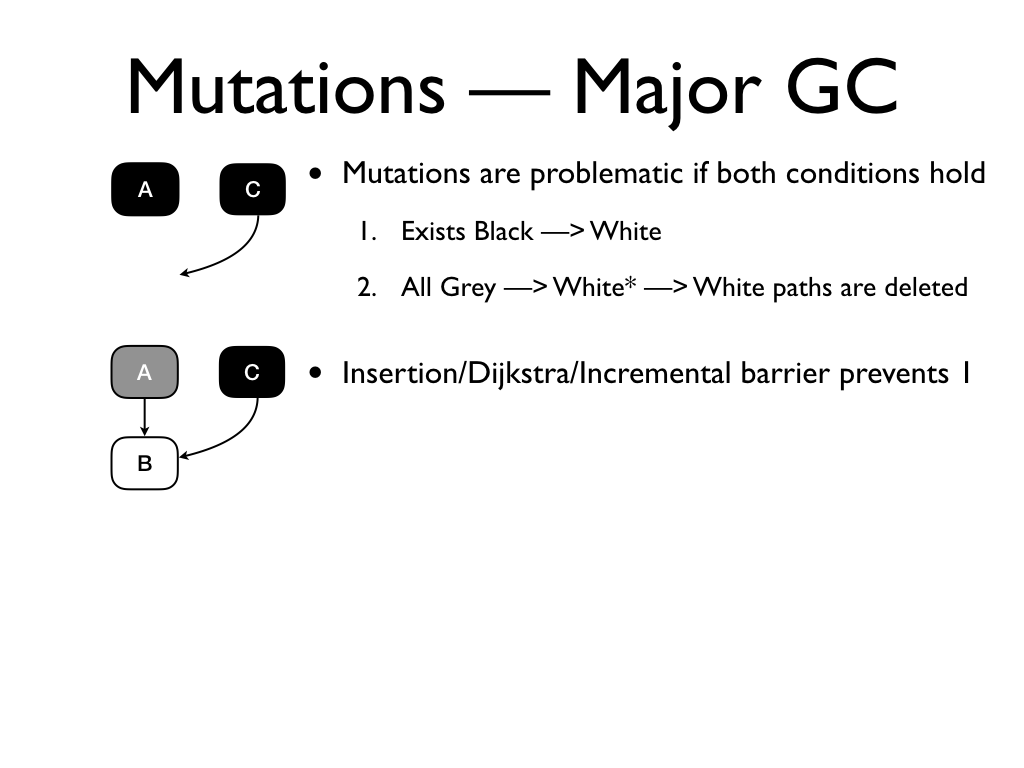
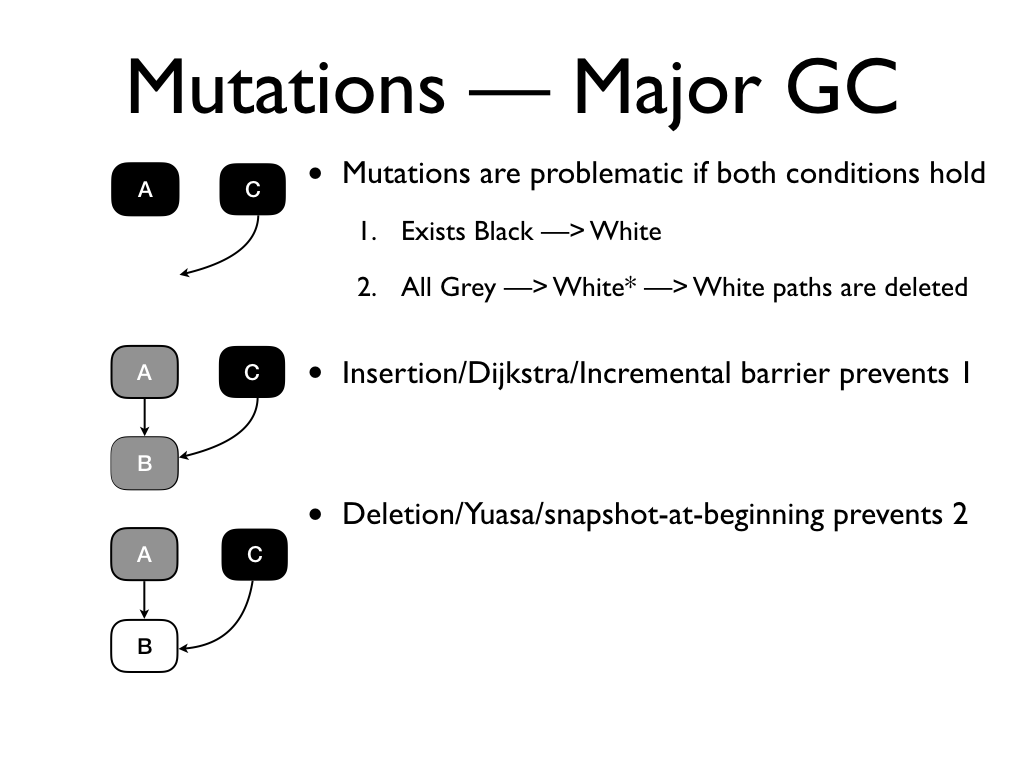
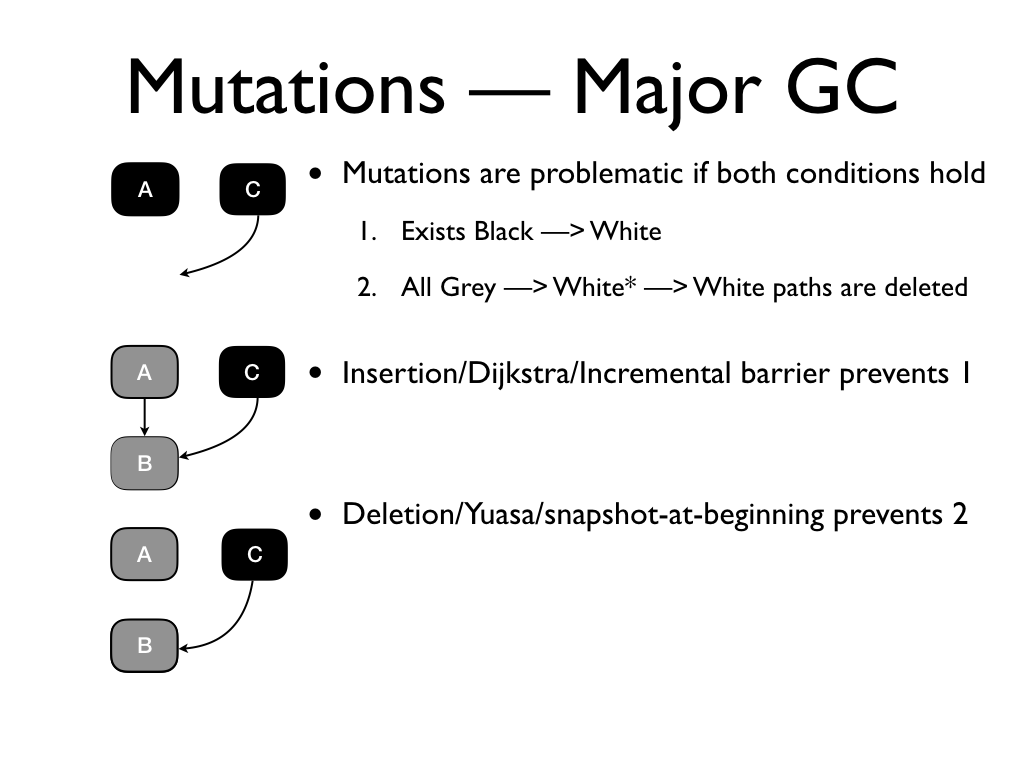
Mutations are problematic if two conditions hold. 1. there exists a black to
white pointer and 2. all references from a grey object through a chain of white
objects to that white object is deleted. We can recover correctness if we
disallow one of these conditions.
An insertion barrier prohibits 1. Whenever a black to white pointer may be
established, the insertion barrier marks the target.
This prevents B from being GCed. The insertion barrier is said to preserve
strong tri-colour invariant: A black object never points to a white
object.
A deletion barrier prohibits 2. In particular, deletion barrier allows the black
to white pointer from C to B.
But when the pointer from the grey A to
the white B is deleted, B is marked. This prevents B from being GCed. The deletion barrier
preserves weak tri-colour invariant: for any white object pointed to by
black object, there exists some grey object from which through a series of white
objects that white object is reachable.
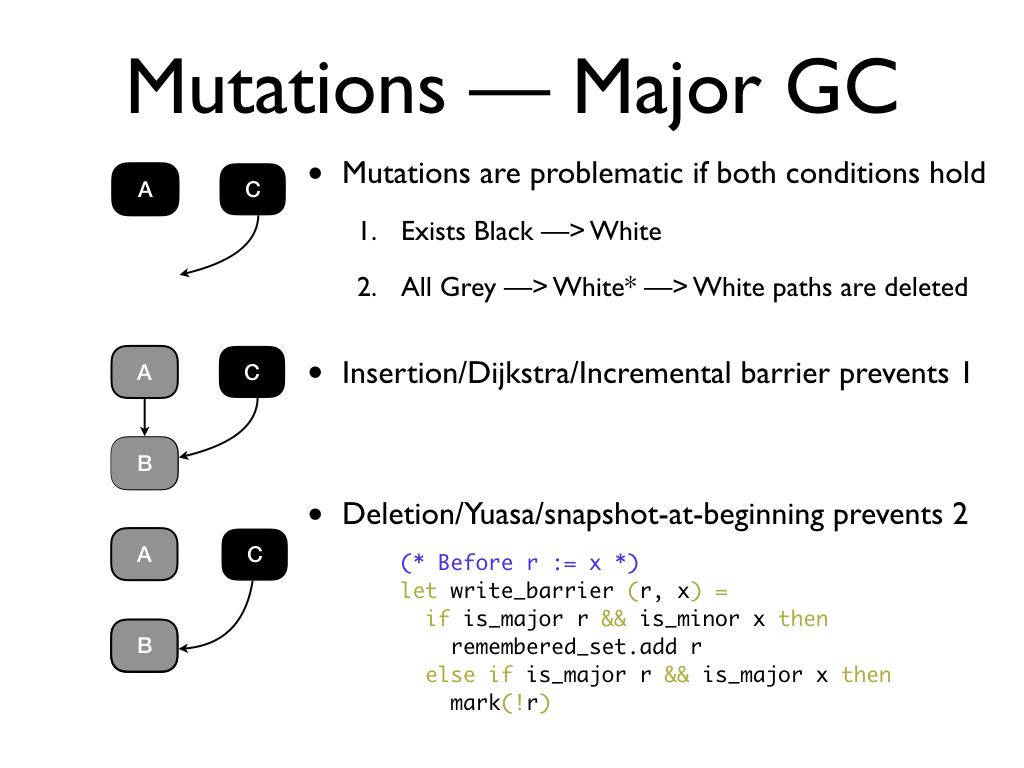
Deletion barrier is used by OCaml. We extend the write barrier to mark the
original object in the reference r if
both r and x are in the major heap.
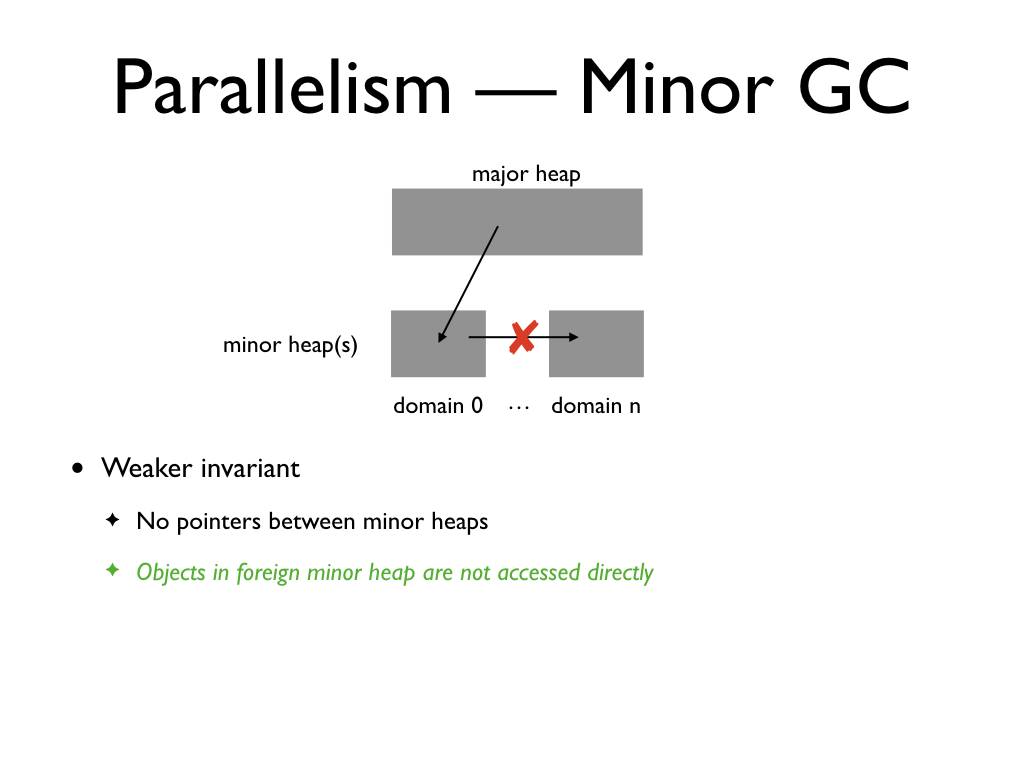
Let us extend the language by adding support for parallel execution. In
Multicore OCaml, Domain.spawn forks off a
new domain to run the thunk in parallel with the calling domain. It is
reasonable to expect that most of the objects in the minor heap are in fact local
to the domain which allocated the object, and are never shared between domains.
Hence, it is desirable to collect each domain's young garbage independently
without having to synchronize all of the domains.
This can be done if the minor heap objects are only accessed by the owning
domain.
In their POPL'93
paper, Doligez and Leroy built a concurrent garbage collector for concurrent
caml light which used domain local heaps. In their paper, the heap invariants
imposed are that there are no pointers between the local heaps and the major
heap does not point to any minor heaps.
These heap invariants are enforced with the help of a write barrier that
intercepts writes, and whenever there is a pointer about to be created between
the major and a minor heap, the transitive closure of the minor heap object is
promoted to the major heap before the assignment.
The problem with this strategy is that we end up with false promotions. Consider
a work stealing queue used for sharing work among multiple domains. It is very
likely that the work-stealing queue survives the minor collection and is
promoted to the major heap. Now, whenever a domain adds work to the queue, the
work needs to be promoted to preserve the heap invariant, even though we expect
that the domain which added the work to consume it in the common case.
Hence, we relax this invariant to allow pointers from major heap to the minor.
We still do not allow pointers between minor heaps, but allow pointers from
major to minor heaps.
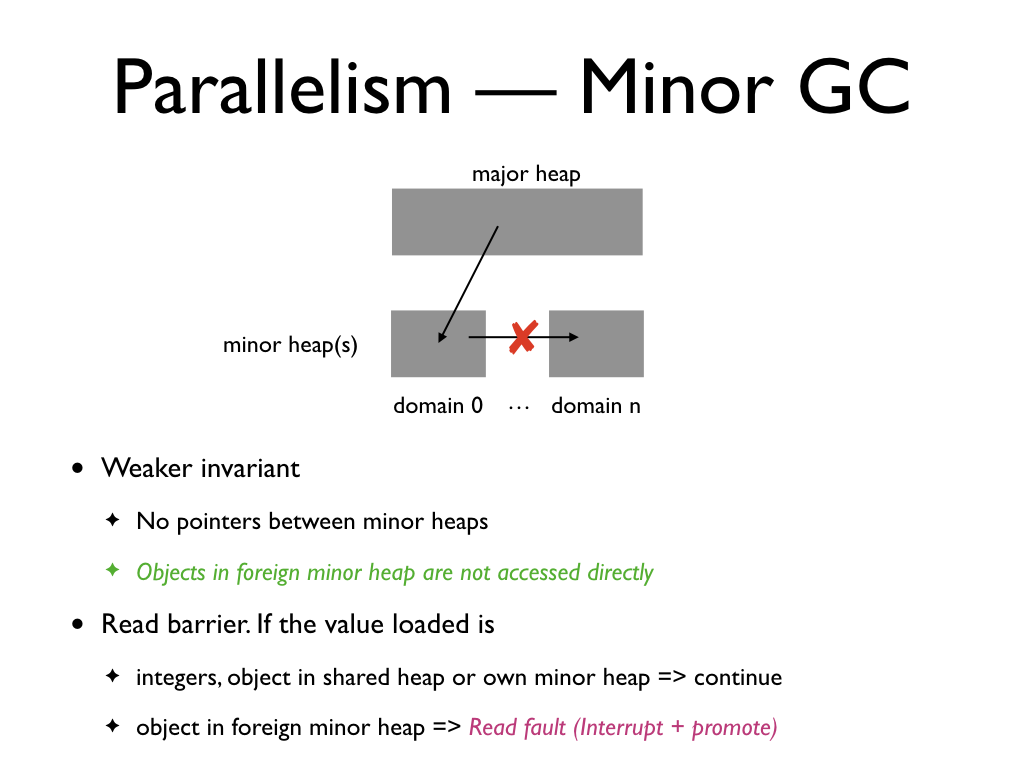
We make sure that a domain does not access objects in a foreign domain with the
help of a read barrier. The read barrier intercepts reads to mutable fields. If
the value loaded is an integer, an object in the shared heap or own minor heap,
then we let the read continue. Otherwise, we interrupt the domain which owns the
object to promote the object closure. This operation returns the new location of
the object in the major heap. This scheme ensures that the minor heaps can be
independently GCed. Marlow
and Peyton Jones evaluated a local heap design with similar weaker heap
invariants for GHC Haskell.
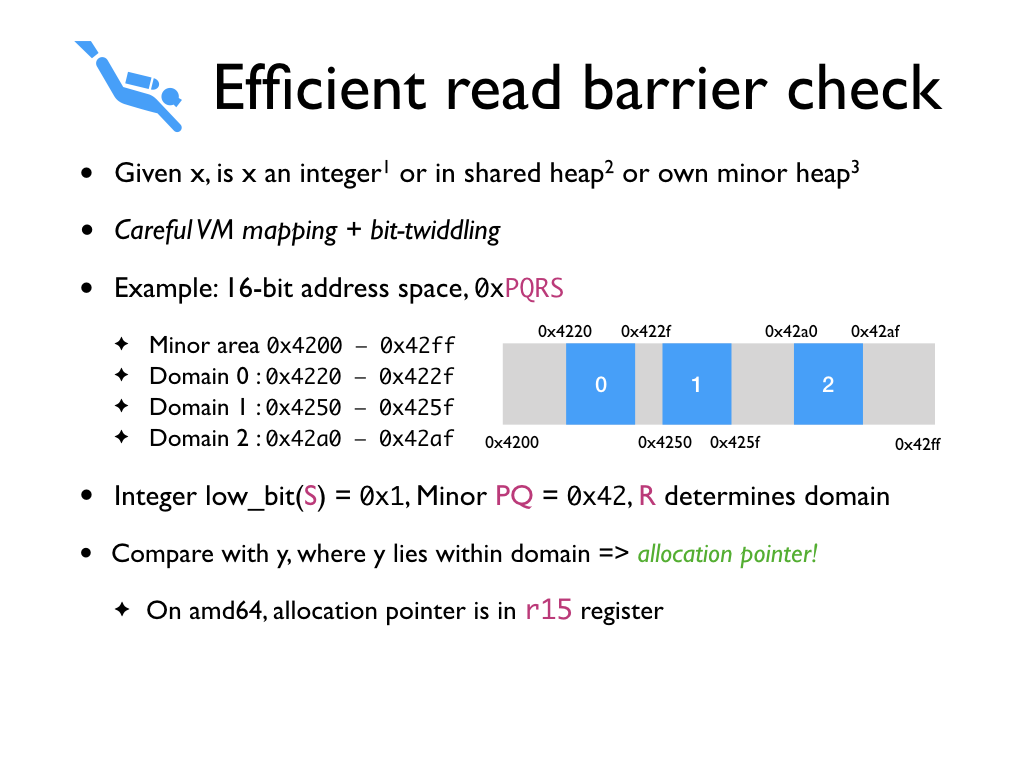
There is a surprisingly efficient way to implement the read barrier checks
through careful virtual memory mapping for minor heaps and a few bit twiddling
tricks. Recall that the fast path for the read barrier is the value read is
either an integer, or a shared heap value, or a value in own minor heap. Let us
assume a 16-bit address space. The minor heap are all allocated in a contiguous
power-of-2 aligned virtual memory area, where each minor heap is also a
power-of-2 aligned and sized. Not all of the virtual memory area need to be
allocated, but only needs to be reserved. In particular, we ensure that shared
heap pages are not allocated in the minor heap area.
Addresses in this 16-bit address space can be written as 4 quads 0xPQRS. In OCaml, integer values are
represented by tagging the least significant bit to be 1. Hence, in this
example, integers have low bit of S to be
1. Minor heap values have PQ to be 42, and R
determines the domain.
We can implement the read barrier check by comparing the given address with an
address from the minor heap. Luckily, we have such an address handily available
in the register -- the allocation pointer. On amd64, the allocation
pointer is in register r15.
Here is our read barrier implementation for amd64 architecture. Assume that the
value of interest is in rax register. At
the end of this sequence of instructions, if none of the enabled bits in 0xff01 are set in rax, then zero flag will be set, and we know
that the value is not a pointer into a foreign minor heap. Let's see how this
works for the different cases.
In the case, of integer, the least significant bit remains set, and hence zero
flag will not be set. We are safe to read this value.
In the case of a shared heap address, the PQ bits will different between r15 and rax. Hence, zero flag will not be set.
In the case of an address in own minor heap, the bits PQR will be the same. Hence, the subtraction
underflows and sets all the bits in PQ.
Hence, the zero flag will not be set.
In the case of an address in foreign minor heap, the bits PQ will be the same. The bits in R will be different, and S will be zero in both values. After xoring,
R will be non-zero and importantly, the
rest of the bits are zero. Subtracting 1 from a non-zero value does not
underflow, hence the rest of the bits remain zero. Now, the zero flag will be
set after the test, and we know that the pointer is in the foreign minor heap.
We now have an efficient way to find out whether we need to promote. But how do
we perform the promotion on a read fault? The general strategy is to interrupt
the foreign domain to perform the promotion for us. There are several
alternatives here.
On receiving the interrupt, the foreign domain may copy the objects from its
minor heap to the major heap. While this strategy works for immutable objects,
mutable objects which are copied should somehow be kept in sync on updates. This
gets tricky especially with relaxed memory behaviours observed on modern
multicore hardware. Moreover, this scheme breaks OCaml objects with Abstract_tag where a C library may map a C
structure onto the OCaml heap and modify it transparently without the knowledge
of the write barrier. Hence, the copies may go out of sync.
We may instead move the object to the major heap and perform a minor GC to fix
any references to the promoted objects. However, this scheme suffers from false
promotions and long pauses during reads. To avoid false promotions, we may
promote the object and scan the roots and the entire minor heap to fix any
references to promoted objects. However, one needs to scan all the objects in
the minor heap, which even the minor collection doesn't have to do.
We make the observation that most objects promoted on read faults happen to be
recently allocated. The reason being that such objects are messages placed into
channels where there is a waiting receiver on the other domain which can consume
the message immediately. In our experiments on a small corpus of parallel OCaml
programs, we found that 95% of objects promoted on read fault are among the
youngest 5%. To make use of this fact, we combine the solutions 2 and 3 from
above.
If the objected to be promoted on read fault is among the youngest x% (in the
current implementation x = 10, but can be dynamically chosen), then we move the
transitive object closure to the major heap. We may have extant pointers into
the promoted objects. We need to fix those pointers such that they point to the
new location of these objects in the major heap. In particular, the pointers may
be found in the roots, objects younger than promoted object in the minor heap,
and older minor objects that point to younger minor objects due to mutations of
older objects. For the latter, we extend the write barrier to record such minor
to minor pointers in promotion_set, which
is only scanned during the promotion process. Otherwise, we move the object
closure and perform a minor GC.
That resolves the major pain points in the interaction of parallelism with minor
GC and promotion. The next is the interplay between parallelism and major GC.
Recall that OCaml's major GC is incremental -- the mutator and the GC (mark and
sweep) take turns to run. If we were to extend the scheme naively to parallel
execution, we would have a stop-the-world incremental collector, where all the
domains have to synchronize for GC work. This would introduce significant
latency overheads. Instead, we go for a concurrent collector design where the
mutator and the GC thread can run in parallel.
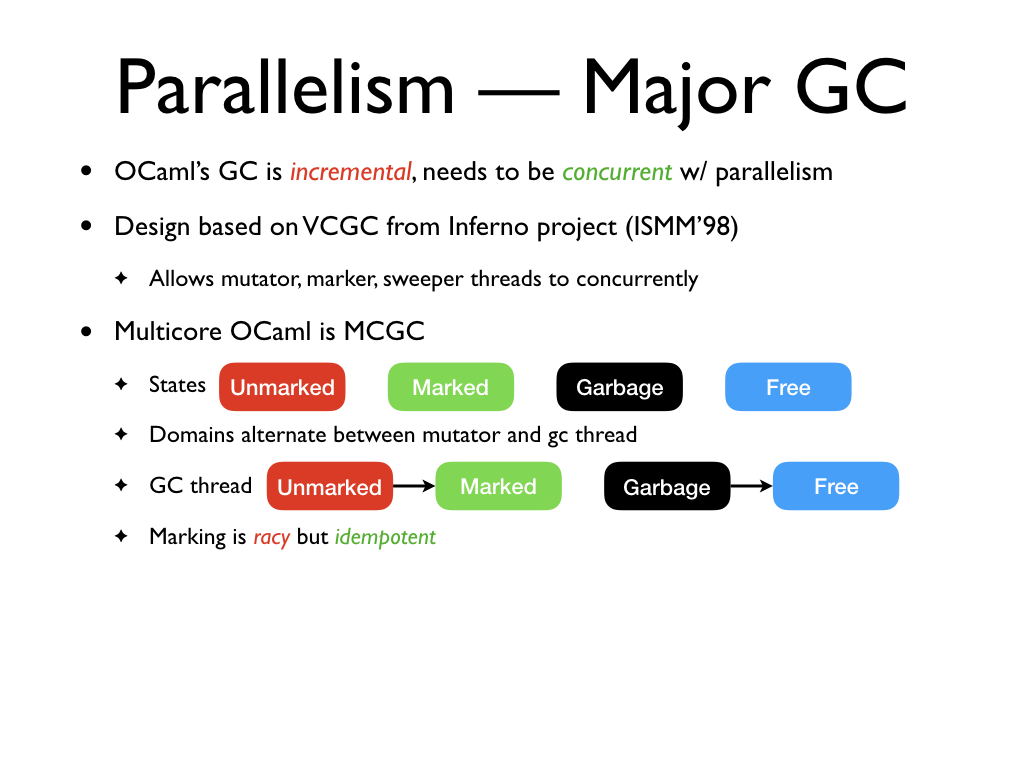
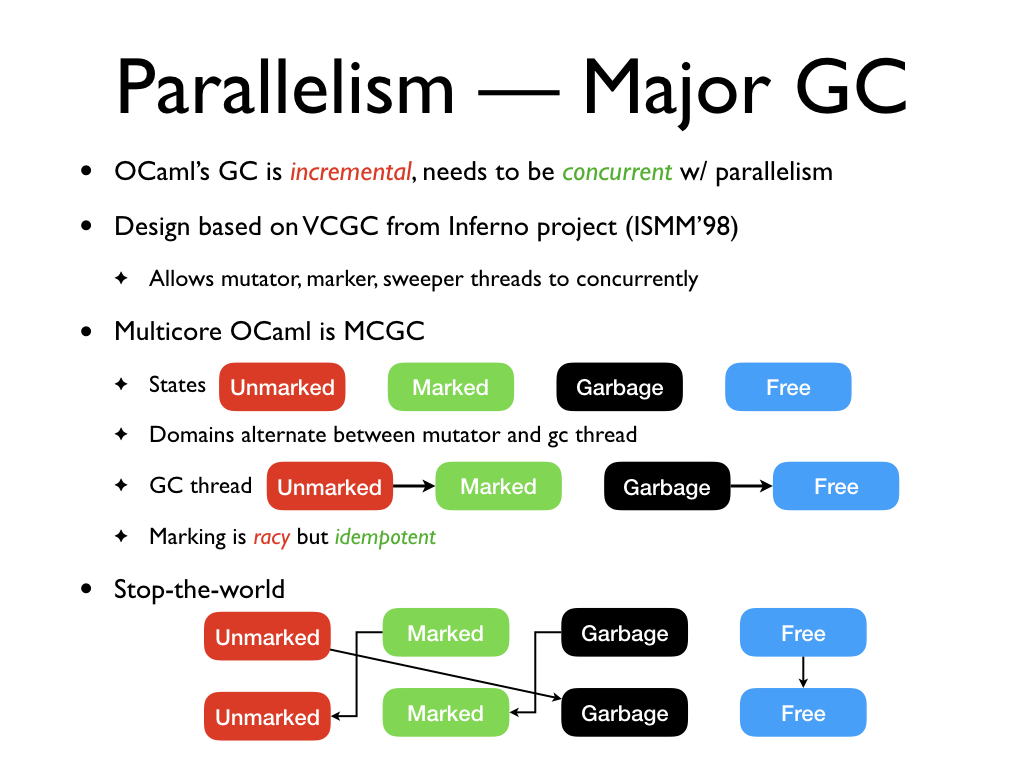
Our design is based on the Very
Concurrent Mark-&-Sweep Garbage Collector (VCGC) design from the Inferno
project which allows the mutator, marker and the sweeper threads to run
concurrently. In VCGC design, there is a small stop-the-world phase at the end
of a cycle where the threads agree on the end of the current major GC cycle and
the beginning of the next one. Multicore OCaml's major GC is mostly concurrent
mark and sweep where the stop-the-world phase might need to do a small fraction
of major GC work left over before the end of the cycle, not unlike the VCGC
design with many mutators i.e., parallel execution.
The major heap objects are in one of the 4 states: Marked, Unmarked, Garbage and Free. The domains alternate between running the
mutator and performing GC work. The GC thread performs a depth-first traversal
of the heap. If it finds an Unmarked
object, it changes its colour to Marked
and pushes the object into a domain-local mark-stack. On the other hand, if it
finds a Garbage object, it marks it as
Free and adds it to the free list. Since
multiple GC threads operate on the heap simultaneously, marking is racy but
idempotent. In particular, there is no synchronization for marking the objects.
If any domain thinks that all the work in the current major GC cycle is done (in
practice, close to being done), it calls for a global synchronization where all
the domains synchronize on the barrier. Once stopped, all the domains work to
actually finish marking, as some work may be left over at other domains. Once
that is done, the cores agree to flip the meaning of the colours. Anything that
is Unmarked is considered Garbage. Anything that is Marked becomes Unmarked for the next cycle. Garbage objects are considered Marked, but at the end of the major GC, all
Garbage objects have been marked Free. Hence, no objects fall into this
category. Anything that is marked Free
still remains Free. This concludes the
discussion on parallelism.
We introduce concurrency into the mix next. Concurrency in Multicore OCaml is
expressed through fibers, which are language-level lightweight threads. Fibers
are implemented as heap allocated, dynamically resized stack segments. Just like
mutating a regular heap object, fibers can also be mutated by pushing and
popping values. However, unlike regular objects, fiber mutations are not
protected by a write barrier. This poses challenges to maintaining the heap
invariants.
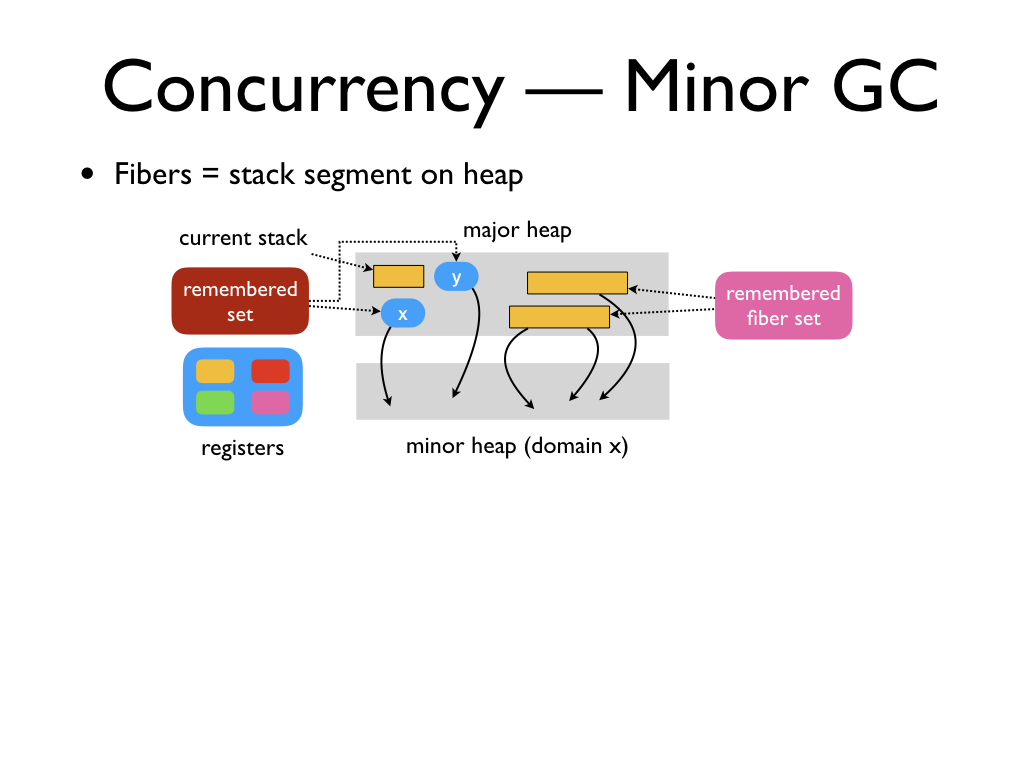
The main thread in Multicore OCaml is also a fiber. Hence, the GC root current
stack is just a pointer to the current fiber. Since we don't have write barrier
on pushing to a fiber, we need to approximate the pointers that may arise from a
fiber in the major heap which points to the minor heap. We do this with the help
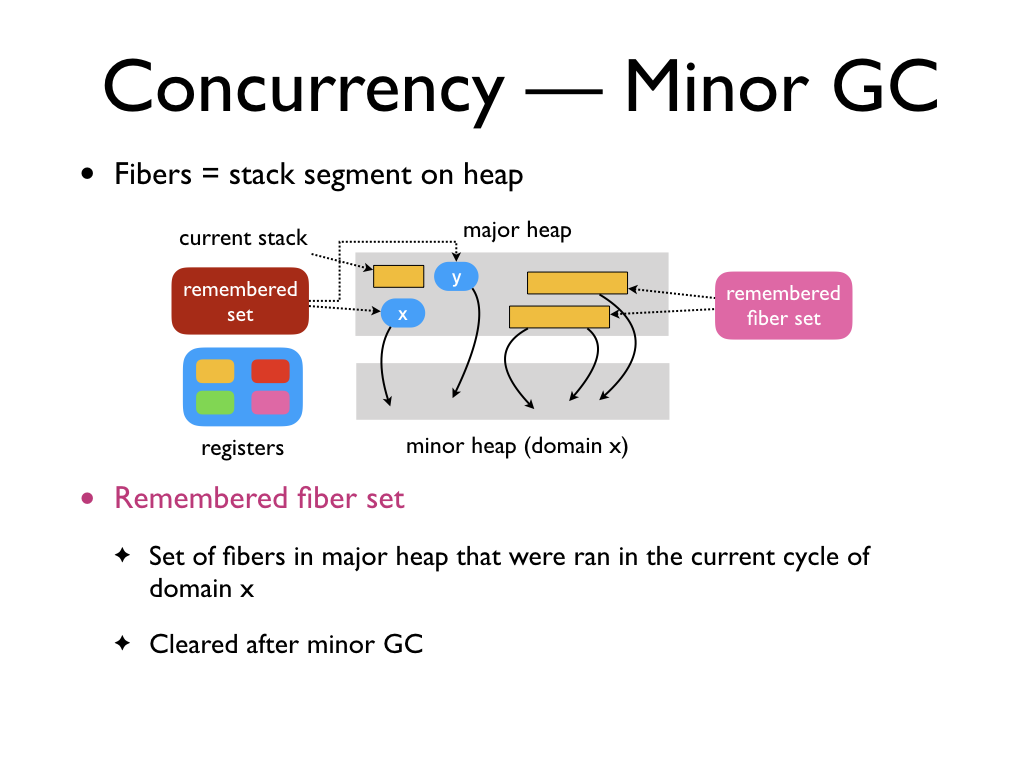
of remembered fiber set.
This represents the set of fibers in the major heap that ran in the current
minor cycle on some domain. Similar to remembered set, the remembered fiber set
is also a domain local data structure. The remembered fiber set is a root for
minor GCs. The remembered fiber set is cleared along with the remembered set at
the end of minor GC.
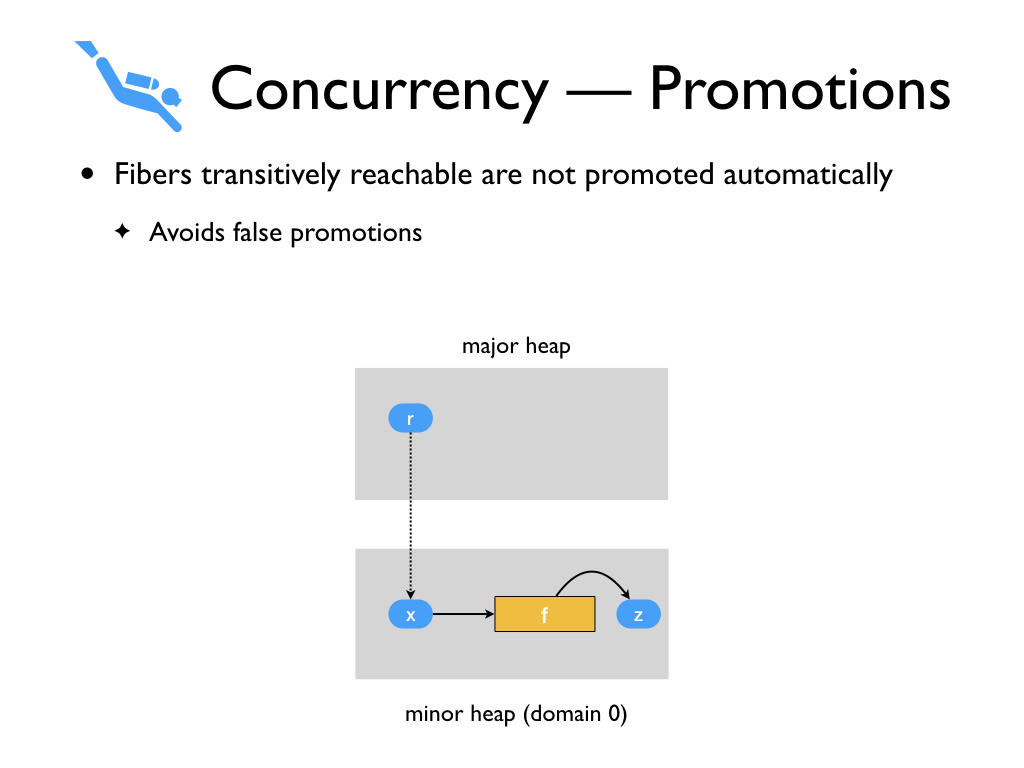
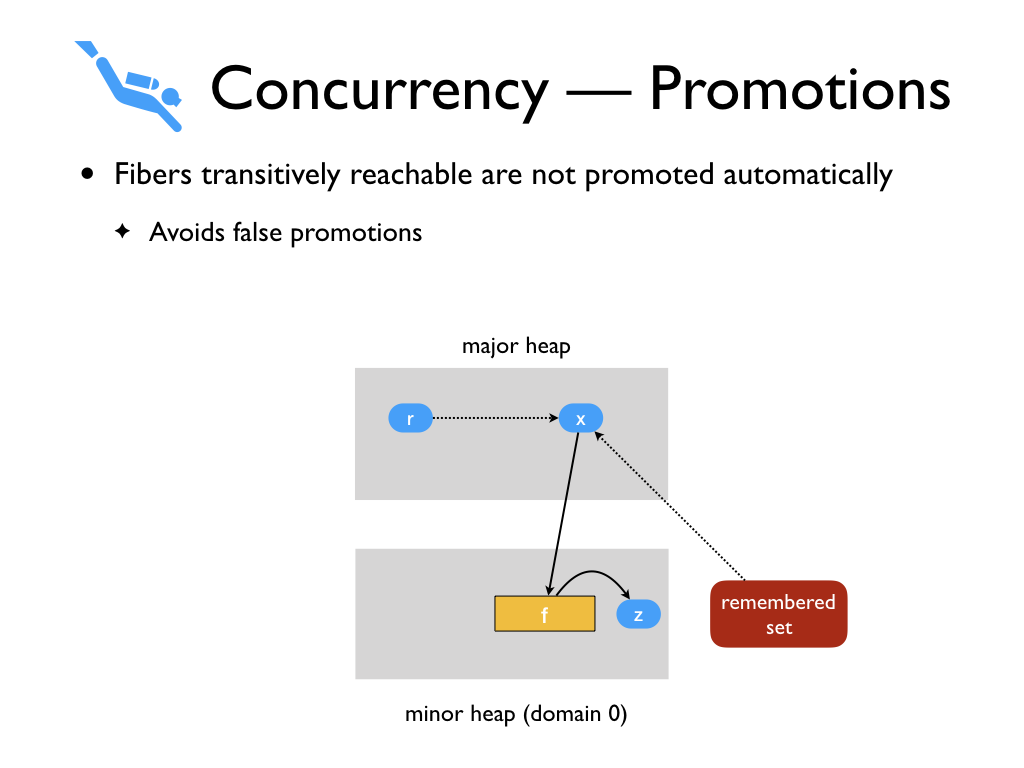
We also treat fibers specially during promotions on read faults. Fibers
transitively reachable are not promoted automatically in order to avoid
prematurely promoting the entire world. We envision work stealing schedulers
where the fiber only needs to be promoted when a different domain explicitly
demands it.
In this example, when assigning x to
r, instead of promoting fiber f,
we leave it on the minor heap. We record x in the remembered set.
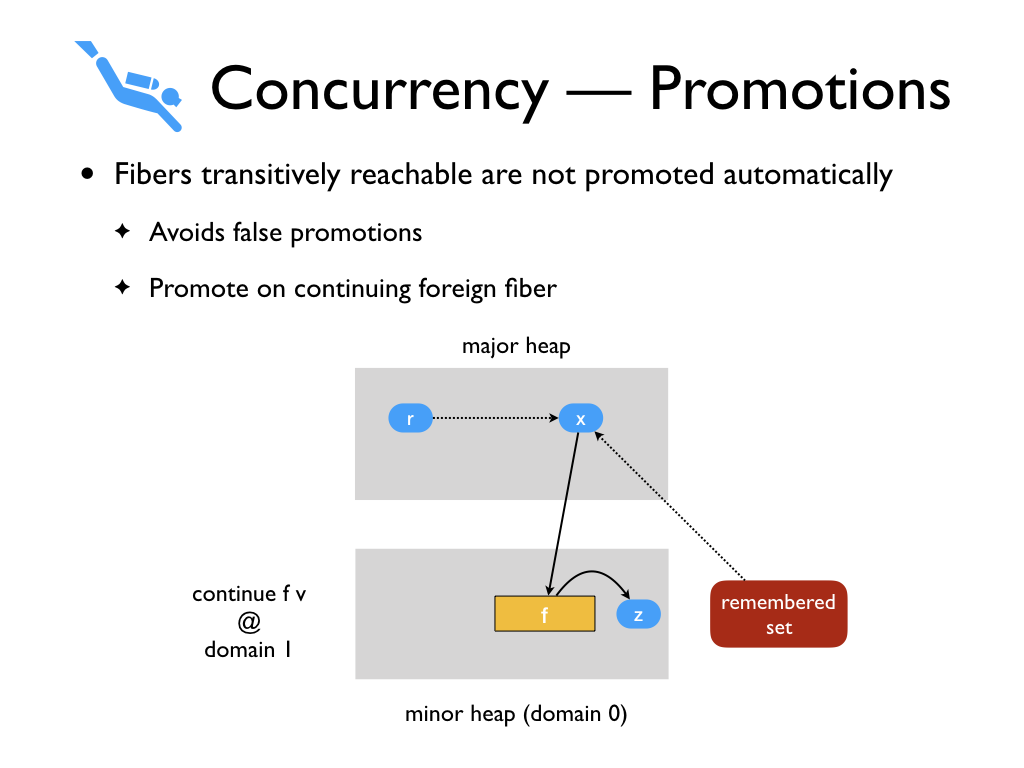
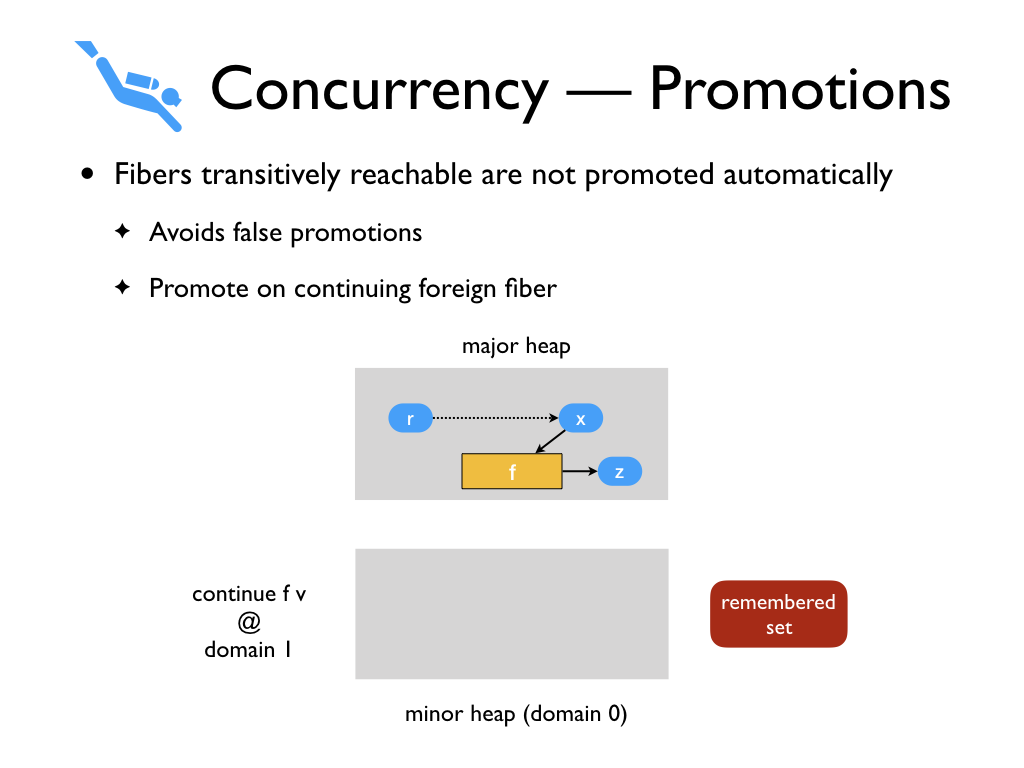
And when a different domain demands it i.e., tries to context switch to the
fiber f,
then we promote the fiber and its transitive closure.
Since we've added the domain-local remembered fiber set, at every instance the
fast path is taken on a read fault, we are obligated to scan this set just after
the promotion is done. But the remembered fiber set may be large, and the fiber
stacks themselves can be large. Hence, scanning the stack for most promotions
would introduce large pause times.
We would like to break up the large pause time if possible. We can do this by
lazily scanning the fibers just before a context switch. We only need to scan a
fiber once per promotion. We also expect the rate of context switches to be much
smaller than the rate of promotions. Hence, in practice, the fiber only gets
scanned once per batch of promotions.
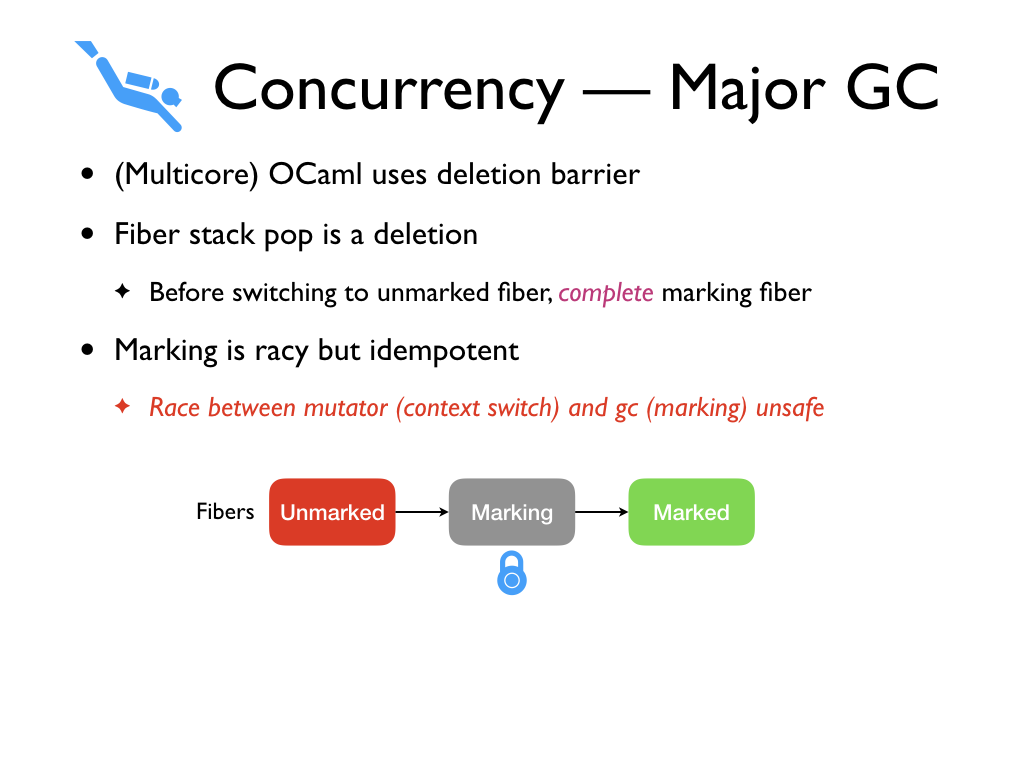
How does concurrency affect the major GC? Recall that Multicore OCaml uses a
deletion barrier. In a deletion barrier, whenever a major heap object loses a
reference to another major heap object, we have to mark the target object.
However, fiber stack pops are not protected by a write barrier. Instead, we
conservatively mark all of the objects on the fiber before switching to it. This
is not to dissimilar to the current stock OCaml compiler scanning the current
stack (as part of the roots) at the beginning of the major GC cycle.
In VCGC, marking is racy but idempotent. Hence, the mutators can freely read and
write the object while it is concurrently marked. In particular, no
synchronization such as compare-and-swap or locks are required to mediate access
between the mutator and the GC thread. However, this invariant does not hold for
fibers. Assume that a mutator is about to context switch to a thread while a GC
thread on another domain attempts to scan and mark the objects on the fiber.
Since the mutator may push and pop the fiber stack, the GC thread concurrently
scanning the stack may observe inconsistent state.
In order to prevent this inconsistency, before switching to a unmarked fiber,
the fiber is marked and all the objects on the fiber are also marked -- fiber is
made Black. And in order to prevent racy
access, the fiber is locked while marking. If the GC thread holds the lock on a
fiber and a mutator tries to context switch to it, the mutator blocks until the
fiber is marked. If the GC thread loses the race, it can safely skip marking the
fiber.
In summary, the Multicore OCaml GC optimizes for latency and minimizes the
maximum pause time through independent minor GCs and a mostly concurrent
mark-and-sweep collector for major GCs. The challenge is to consider the
interactions between mutations, concurrency and parallelism and the various GC
techniques in order to come up with a design that preserves safety and optimizes
our performance goals. I will have to save the performance analysis of the GC to
a different talk.